Hey all,
This is my first time posting on here (I believe at least) so please bear with me as I'm trying to figure out some performance concerns we're having with some hosted VMs. Our testing consisted of both dd (which I read wasn't necessarily satisfactory with PVE) as well as "fio".
I have 2x clusters, one with 10x servers and another cluster with 5x servers - both with Ceph for storage and both are getting poor write performance within VMs.
After reading many articles and discussions, I have tried quite a few things all to no avail EXCEPT the SSD aspect. The reason is, how much better can I expect? Would I need to get top quality SSDs to really make an impact?
My PVE host itself gets decent performance (using dd, at least - see attachment 5.12.44), the hosted VMs are the issue at hand. Most testing VMs are CentOS7.
The physical hardware:
R610s all around
4x 4TB 5400 RPMs for storage (I know, I know, poor speeds but they were the best suited drive for what we need and budget)
96 GB of RAM each
1x SAS drive for the PVE host install OS (I forget the speed but definitely better than 5400 RPM)
10Gb isolated network for Ceph
1Gb for WAN / cluster sync
That said, I saw the sample command using fio as described in this wiki link. This seems to be a read command though and not write (per the command flags; i.e., "--rw=read"). I looked up other tutorials for fio and found this command:
fio --name=seqwrite --rw=write --direct=1 --ioengine=libaio --bs=4M --numjobs=4 --size=1G --runtime=600 --group_reporting
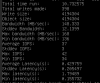
My results are in screenshot (5.17.16). I interpret that (164,282KB => 164.282MB) as not too shabby. Am I right here?
The dd command isn't too bad either (5.12.44) screenshot.
I read that the default block size of ceph pools is 4M per that wiki discussing fio in the first place. This is the same block size I used for both tests: dd and fio.
Now when I test within a CentOS7 VM, "bs=4K":
dd results are (5.22.21)
fio command with "--bs=4M" results are (5.38.31)
So what can I do?
Do allocated resources for VMs matter in this case? We'd like not to use any caching for obvious reasons (I saw many "no-nos" in this regard from other forums).
I tried this none authentication route but that seemed to make things worse so I reverted.
I tried reducing replication size to just 1, same thing.
I didn't try SSDs and we're willing to go this route but would prefer not to. We have a handful of servers that don't need the write performance but some require it, so we're thinking of a dedicated SSD pool via the CRUSH commands.
If I am missing any data, please let me know and I'll get it ASAP.
Thanks
This is my first time posting on here (I believe at least) so please bear with me as I'm trying to figure out some performance concerns we're having with some hosted VMs. Our testing consisted of both dd (which I read wasn't necessarily satisfactory with PVE) as well as "fio".
I have 2x clusters, one with 10x servers and another cluster with 5x servers - both with Ceph for storage and both are getting poor write performance within VMs.
After reading many articles and discussions, I have tried quite a few things all to no avail EXCEPT the SSD aspect. The reason is, how much better can I expect? Would I need to get top quality SSDs to really make an impact?
My PVE host itself gets decent performance (using dd, at least - see attachment 5.12.44), the hosted VMs are the issue at hand. Most testing VMs are CentOS7.
The physical hardware:
R610s all around
4x 4TB 5400 RPMs for storage (I know, I know, poor speeds but they were the best suited drive for what we need and budget)
96 GB of RAM each
1x SAS drive for the PVE host install OS (I forget the speed but definitely better than 5400 RPM)
10Gb isolated network for Ceph
1Gb for WAN / cluster sync
That said, I saw the sample command using fio as described in this wiki link. This seems to be a read command though and not write (per the command flags; i.e., "--rw=read"). I looked up other tutorials for fio and found this command:
fio --name=seqwrite --rw=write --direct=1 --ioengine=libaio --bs=4M --numjobs=4 --size=1G --runtime=600 --group_reporting
My results are in screenshot (5.17.16). I interpret that (164,282KB => 164.282MB) as not too shabby. Am I right here?
The dd command isn't too bad either (5.12.44) screenshot.
I read that the default block size of ceph pools is 4M per that wiki discussing fio in the first place. This is the same block size I used for both tests: dd and fio.
Now when I test within a CentOS7 VM, "bs=4K":
dd results are (5.22.21)
fio command with "--bs=4M" results are (5.38.31)
So what can I do?
Do allocated resources for VMs matter in this case? We'd like not to use any caching for obvious reasons (I saw many "no-nos" in this regard from other forums).
I tried this none authentication route but that seemed to make things worse so I reverted.
I tried reducing replication size to just 1, same thing.
I didn't try SSDs and we're willing to go this route but would prefer not to. We have a handful of servers that don't need the write performance but some require it, so we're thinking of a dedicated SSD pool via the CRUSH commands.
If I am missing any data, please let me know and I'll get it ASAP.
Thanks