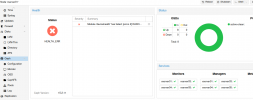
Hi, ive got a little problem, ceph cluster works but one pg is unknown.
I think ist because the pool health_metric has no osd.
This Ceph cluster exist before the pool health_metric published from installer.
But i mean that the pool exist before the update on a higher version from nautilus.
Ive upgraded to octopus yet.
I think this error occours, because this pool has no OSD.
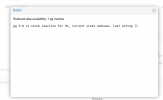
if i try
ceph pg repair 3.0
then
Error EAGAIN: pg 3.0 has no primary osd
So i think thats the problem, metric pool has no OSD, i think.
I had an nvme pool only. I had two rulesets. the standard and nvme
The Health metric pool has default ruleset.
I dont want insert hdds as OSD only for health_metric.
Must i change the health_pool rule to nvme rule? When yes without data loss from my nvme pool?
Or how can i this fixed?
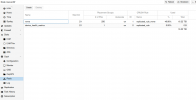
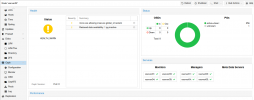
See screenshots.
In Screenshots Ive got a second waring:
mon.vserver03 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver04 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver05 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver01 has auth_allow_insecure_global_id_reclaim set to true
But this will i solve later or depends my problem on it?
Thank you!
Sincerely Bonkersdeluxe
my Crush map
I think ist because the pool health_metric has no osd.
This Ceph cluster exist before the pool health_metric published from installer.
But i mean that the pool exist before the update on a higher version from nautilus.
Ive upgraded to octopus yet.
I think this error occours, because this pool has no OSD.
if i try
ceph pg repair 3.0
then
Error EAGAIN: pg 3.0 has no primary osd
So i think thats the problem, metric pool has no OSD, i think.
I had an nvme pool only. I had two rulesets. the standard and nvme
The Health metric pool has default ruleset.
I dont want insert hdds as OSD only for health_metric.
Must i change the health_pool rule to nvme rule? When yes without data loss from my nvme pool?
Or how can i this fixed?
See screenshots.
In Screenshots Ive got a second waring:
mon.vserver03 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver04 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver05 has auth_allow_insecure_global_id_reclaim set to true
mon.vserver01 has auth_allow_insecure_global_id_reclaim set to true
But this will i solve later or depends my problem on it?
Thank you!
Sincerely Bonkersdeluxe
my Crush map
Code:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class nvme
device 1 osd.1 class nvme
device 2 osd.2 class nvme
device 3 osd.3 class nvme
device 4 osd.4 class nvme
device 5 osd.5 class nvme
device 11 osd.11 class nvme
device 12 osd.12 class nvme
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host vserver01 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
id -9 class nvme # do not change unnecessarily
# weight 11.644
alg straw2
hash 0 # rjenkins1
item osd.4 weight 5.822
item osd.5 weight 5.822
}
host vserver02 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
id -10 class nvme # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
host vserver03 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
id -11 class nvme # do not change unnecessarily
# weight 5.820
alg straw2
hash 0 # rjenkins1
item osd.11 weight 2.910
item osd.12 weight 2.910
}
host vserver04 {
id -13 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
id -15 class nvme # do not change unnecessarily
# weight 11.644
alg straw2
hash 0 # rjenkins1
item osd.0 weight 5.822
item osd.1 weight 5.822
}
host vserver05 {
id -16 # do not change unnecessarily
id -17 class hdd # do not change unnecessarily
id -18 class nvme # do not change unnecessarily
# weight 11.644
alg straw2
hash 0 # rjenkins1
item osd.2 weight 5.822
item osd.3 weight 5.822
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
id -12 class nvme # do not change unnecessarily
# weight 40.752
alg straw2
hash 0 # rjenkins1
item vserver01 weight 11.644
item vserver02 weight 0.000
item vserver03 weight 5.820
item vserver04 weight 11.644
item vserver05 weight 11.644
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
rule replicated_rule_nvme {
id 1
type replicated
min_size 1
max_size 10
step take default class nvme
step chooseleaf firstn 0 type host
step emit
}
# end crush mapAttachments
Last edited: