Hello fellow ProxMoxers!
I am running a home server with a machine with lower hardware.
It is working... fine, but sometimes the web interface simply get me nuts!
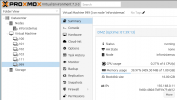
All VMs show a unkonwn status and hide their IDs and names. With a reboot everything comes back fine. But the idea is 24/7 availability.
The Web interface is as the file attachment
How to revert this on a running instance and prevent it from happening again?
Thanks!
I am running a home server with a machine with lower hardware.
Code:
4 x Intel(R) Core(TM) i5-3330 CPU @ 3.00GHz
1 X 8Gb Ram DDR3It is working... fine, but sometimes the web interface simply get me nuts!
All VMs show a unkonwn status and hide their IDs and names. With a reboot everything comes back fine. But the idea is 24/7 availability.
The Web interface is as the file attachment
How to revert this on a running instance and prevent it from happening again?
Thanks!