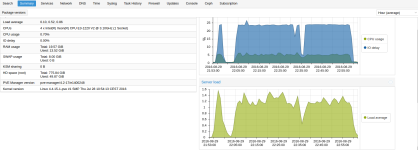
i run proxmox 4.2 on HP server with a Xeon 1220v2 Cpu, 20gb of ecc ram. i am seeing massive performance issues and i can't find the reason why.
I run 2 mirros on on a Intel RS2WC080, last week i decided to remove the raid controller and try on the onboard sata. the problem stil exist. i benchamrked the drives before the where put into the proxmox node there they performed as aspected on ext4
The issue is only on the rpool, all smart data is passed and i have tested with no running vm's or containers,
the config for the pool:
RPOOL: sdc + sdd 2x SAMSUNG MZ7TE128HMGR
root@vmcluster01:~# zpool get all rpool
NAME PROPERTY VALUE SOURCE
rpool size 119G -
rpool capacity 50% -
rpool altroot - default
rpool health ONLINE -
rpool guid 5425977347035108410 default
rpool version - default
rpool bootfs rpool/ROOT/pve-1 local
rpool delegation on default
rpool autoreplace off default
rpool cachefile - default
rpool failmode wait default
rpool listsnapshots off default
rpool autoexpand off default
rpool dedupditto 0 default
rpool dedupratio 1.00x -
rpool free 58.8G -
rpool allocated 60.2G -
rpool readonly off -
rpool ashift 12 local
rpool comment - default
rpool expandsize - -
rpool freeing 0 default
rpool fragmentation 44% -
rpool leaked 0 default
rpool feature@async_destroy enabled local
rpool feature@empty_bpobj active local
rpool feature@lz4_compress active local
rpool feature@spacemap_histogram active local
rpool feature@enabled_txg active local
rpool feature@hole_birth active local
rpool feature@extensible_dataset enabled local
rpool feature@embedded_data active local
rpool feature@bookmarks enabled local
rpool feature@filesystem_limits enabled local
rpool feature@large_blocks enabled local
DATASTORE: sda + sdb 2 x 3TB Seagate disks
root@vmcluster01:~# zpool get all datastore
NAME PROPERTY VALUE SOURCE
datastore size 2.72T -
datastore capacity 48% -
datastore altroot - default
datastore health ONLINE -
datastore guid 6264853520651431196 default
datastore version - default
datastore bootfs - default
datastore delegation on default
datastore autoreplace off default
datastore cachefile - default
datastore failmode wait default
datastore listsnapshots off default
datastore autoexpand off default
datastore dedupditto 0 default
datastore dedupratio 1.00x -
datastore free 1.40T -
datastore allocated 1.32T -
datastore readonly off -
datastore ashift 12 local
datastore comment - default
datastore expandsize - -
datastore freeing 0 default
datastore fragmentation 11% -
datastore leaked 0 default
datastore feature@async_destroy enabled local
datastore feature@empty_bpobj active local
datastore feature@lz4_compress active local
datastore feature@spacemap_histogram active local
datastore feature@enabled_txg active local
datastore feature@hole_birth active local
datastore feature@extensible_dataset enabled local
datastore feature@embedded_data active local
datastore feature@bookmarks enabled local
datastore feature@filesystem_limits enabled local
datastore feature@large_blocks enabled local
Some tests:
i have tried creating different storagetypes to se if there is a difference in the performance.
there is no difference in running as "directory" or "zfs"
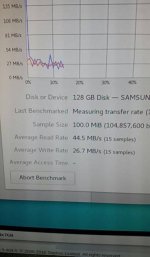
When coping a vm from from rpool to datastore it looks okay, 100-152MB write (on reagular disk is okay)
datastore 1.32T 1.40T 0 1.19K 0 152M
rpool 61.6G 57.4G 8.81K 0 67.9M 8.00K
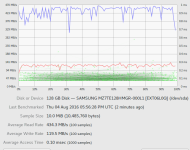
but when When cloning a vm from from Datastore to rpool or from rpool to rpool is look horrible like this 5-12.6Mb on SSD
capacity operations bandwidth
pool alloc free read write read write
datastore 1.32T 1.40T 756 0 93.9M 0
rpool 61.5G 57.5G 4 1.04K 60.0K 12.6M
This is the ouput from iostat when cloning a vm from rpool to rpool, sdc and sdd is utilized 100% with iowait/delay going from 5%-50%
but the wierd part is my cpu is not going over 10% in cpu utilization, the questions is why are the disks utilized a 100% and performing so bad.
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 23.00 0.00 42.00 102.00 4.19 12.11 231.78 2.74 19.28 35.62 12.55 6.94 100.00
sdd 31.00 0.00 54.00 71.00 8.13 8.39 270.66 3.08 25.47 36.30 17.24 8.00 100.00
zd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd16 0.00 0.00 0.00 4.00 0.00 0.01 4.00 0.32 79.00 0.00 79.00 79.00 31.60
zd32 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd48 0.00 0.00 96.00 0.00 12.00 0.00 256.00 0.99 10.46 10.46 0.00 10.29 98.80
zd64 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd80 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd96 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Another iostat view:
avg-cpu: %user %nice %system %iowait %steal %idle
0.75 0.00 5.51 37.59 0.00 56.14
when i look at zfs list i can se there is no compress on datastore ?
root@vmcluster01:~# zfs list -o name,compression,recordsize
NAME COMPRESS RECSIZE
datastore off 128K
datastore/files off 128K
rpool lz4 128K
rpool/ROOT lz4 128K
rpool/ROOT/pve-1 lz4 128K
rpool/ct lz4 128K
rpool/ct/subvol-1910-disk-1 lz4 128K
rpool/ct/subvol-1920-disk-2 lz4 128K
rpool/ct/subvol-1930-disk-1 lz4 128K
rpool/ct/vm-112-disk-1 lz4 -
rpool/ct/vm-114-disk-1 lz4 -
rpool/ct/vm-1180-disk-1 lz4 -
rpool/ct/vm-1190-disk-1 lz4 -
rpool/ct/vm-1810-disk-1 lz4 -
rpool/swap lz4 -
I run 2 mirros on on a Intel RS2WC080, last week i decided to remove the raid controller and try on the onboard sata. the problem stil exist. i benchamrked the drives before the where put into the proxmox node there they performed as aspected on ext4
The issue is only on the rpool, all smart data is passed and i have tested with no running vm's or containers,
the config for the pool:
RPOOL: sdc + sdd 2x SAMSUNG MZ7TE128HMGR
root@vmcluster01:~# zpool get all rpool
NAME PROPERTY VALUE SOURCE
rpool size 119G -
rpool capacity 50% -
rpool altroot - default
rpool health ONLINE -
rpool guid 5425977347035108410 default
rpool version - default
rpool bootfs rpool/ROOT/pve-1 local
rpool delegation on default
rpool autoreplace off default
rpool cachefile - default
rpool failmode wait default
rpool listsnapshots off default
rpool autoexpand off default
rpool dedupditto 0 default
rpool dedupratio 1.00x -
rpool free 58.8G -
rpool allocated 60.2G -
rpool readonly off -
rpool ashift 12 local
rpool comment - default
rpool expandsize - -
rpool freeing 0 default
rpool fragmentation 44% -
rpool leaked 0 default
rpool feature@async_destroy enabled local
rpool feature@empty_bpobj active local
rpool feature@lz4_compress active local
rpool feature@spacemap_histogram active local
rpool feature@enabled_txg active local
rpool feature@hole_birth active local
rpool feature@extensible_dataset enabled local
rpool feature@embedded_data active local
rpool feature@bookmarks enabled local
rpool feature@filesystem_limits enabled local
rpool feature@large_blocks enabled local
DATASTORE: sda + sdb 2 x 3TB Seagate disks
root@vmcluster01:~# zpool get all datastore
NAME PROPERTY VALUE SOURCE
datastore size 2.72T -
datastore capacity 48% -
datastore altroot - default
datastore health ONLINE -
datastore guid 6264853520651431196 default
datastore version - default
datastore bootfs - default
datastore delegation on default
datastore autoreplace off default
datastore cachefile - default
datastore failmode wait default
datastore listsnapshots off default
datastore autoexpand off default
datastore dedupditto 0 default
datastore dedupratio 1.00x -
datastore free 1.40T -
datastore allocated 1.32T -
datastore readonly off -
datastore ashift 12 local
datastore comment - default
datastore expandsize - -
datastore freeing 0 default
datastore fragmentation 11% -
datastore leaked 0 default
datastore feature@async_destroy enabled local
datastore feature@empty_bpobj active local
datastore feature@lz4_compress active local
datastore feature@spacemap_histogram active local
datastore feature@enabled_txg active local
datastore feature@hole_birth active local
datastore feature@extensible_dataset enabled local
datastore feature@embedded_data active local
datastore feature@bookmarks enabled local
datastore feature@filesystem_limits enabled local
datastore feature@large_blocks enabled local
Some tests:
i have tried creating different storagetypes to se if there is a difference in the performance.
there is no difference in running as "directory" or "zfs"
When coping a vm from from rpool to datastore it looks okay, 100-152MB write (on reagular disk is okay)
datastore 1.32T 1.40T 0 1.19K 0 152M
rpool 61.6G 57.4G 8.81K 0 67.9M 8.00K
but when When cloning a vm from from Datastore to rpool or from rpool to rpool is look horrible like this 5-12.6Mb on SSD
capacity operations bandwidth
pool alloc free read write read write
datastore 1.32T 1.40T 756 0 93.9M 0
rpool 61.5G 57.5G 4 1.04K 60.0K 12.6M
This is the ouput from iostat when cloning a vm from rpool to rpool, sdc and sdd is utilized 100% with iowait/delay going from 5%-50%
but the wierd part is my cpu is not going over 10% in cpu utilization, the questions is why are the disks utilized a 100% and performing so bad.
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 23.00 0.00 42.00 102.00 4.19 12.11 231.78 2.74 19.28 35.62 12.55 6.94 100.00
sdd 31.00 0.00 54.00 71.00 8.13 8.39 270.66 3.08 25.47 36.30 17.24 8.00 100.00
zd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd16 0.00 0.00 0.00 4.00 0.00 0.01 4.00 0.32 79.00 0.00 79.00 79.00 31.60
zd32 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd48 0.00 0.00 96.00 0.00 12.00 0.00 256.00 0.99 10.46 10.46 0.00 10.29 98.80
zd64 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd80 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
zd96 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Another iostat view:
avg-cpu: %user %nice %system %iowait %steal %idle
0.75 0.00 5.51 37.59 0.00 56.14
when i look at zfs list i can se there is no compress on datastore ?
root@vmcluster01:~# zfs list -o name,compression,recordsize
NAME COMPRESS RECSIZE
datastore off 128K
datastore/files off 128K
rpool lz4 128K
rpool/ROOT lz4 128K
rpool/ROOT/pve-1 lz4 128K
rpool/ct lz4 128K
rpool/ct/subvol-1910-disk-1 lz4 128K
rpool/ct/subvol-1920-disk-2 lz4 128K
rpool/ct/subvol-1930-disk-1 lz4 128K
rpool/ct/vm-112-disk-1 lz4 -
rpool/ct/vm-114-disk-1 lz4 -
rpool/ct/vm-1180-disk-1 lz4 -
rpool/ct/vm-1190-disk-1 lz4 -
rpool/ct/vm-1810-disk-1 lz4 -
rpool/swap lz4 -
Last edited:


")