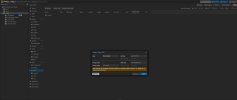
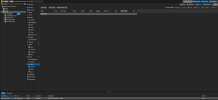
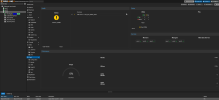
I have the exact same issue too, I can't get OSDs at all, I wonder if this is an issue with squid?
Edit: just noticed this in the logs
root@Instalation01:~# systemctl status ceph-osd@1
×
ceph-osd@1.service - Ceph object storage daemon osd.1
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: failed (Result: exit-code) since Tue 2025-03-11 23:13:29 MST; 10s ago
Duration: 827ms
Process: 19663 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 1 (code=exited, status=0/SUCCESS)
Process: 19668 ExecStart=/usr/bin/ceph-osd -f --cluster ${CLUSTER} --id 1 --setuser ceph --setgroup ceph (code=exited, status=1/FAILURE)
Main PID: 19668 (code=exited, status=1/FAILURE)
CPU: 97ms
Mar 11 23:13:29 Instalation01 systemd[1]:
ceph-osd@1.service: Scheduled restart job, restart counter is at 3.
Mar 11 23:13:29 Instalation01 systemd[1]: Stopped
ceph-osd@1.service - Ceph object storage daemon osd.1.
Mar 11 23:13:29 Instalation01 systemd[1]:
ceph-osd@1.service: Start request repeated too quickly.
Mar 11 23:13:29 Instalation01 systemd[1]:
ceph-osd@1.service: Failed with result 'exit-code'.
Mar 11 23:13:29 Instalation01 systemd[1]: Failed to start
ceph-osd@1.service - Ceph object storage daemon osd.1.
also attached is my log file
Edit again
root@Instalation01:~# systemctl status ceph-osd@0
●
ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: activating (auto-restart) (Result: exit-code) since Tue 2025-03-11 23:19:38 MST; 2s ago
Process: 21808 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 0 (code=exited, status=0/SUCCESS)
Process: 21819 ExecStart=/usr/bin/ceph-osd -f --cluster ${CLUSTER} --id 0 --setuser ceph --setgroup ceph (code=exited, status=1/FAILURE)
Main PID: 21819 (code=exited, status=1/FAILURE)
CPU: 99ms
root@Instalation01:~# systemctl status ceph-osd@0
●
ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: active (running) since Tue 2025-03-11 23:19:48 MST; 679ms ago
Process: 22076 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 0 (code=exited, status=0/SUCCESS)
Main PID: 22099 (ceph-osd)
Tasks: 8
Memory: 11.2M
CPU: 97ms
CGroup: /system.slice/system-ceph\x2dosd.slice/
ceph-osd@0.service
└─22099 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
Mar 11 23:19:48 Instalation01 systemd[1]: Starting
ceph-osd@0.service - Ceph object storage daemon osd.0...
Mar 11 23:19:48 Instalation01 systemd[1]: Started
ceph-osd@0.service - Ceph object storage daemon osd.0.
root@Instalation01:~# systemctl status ceph-osd@0
●
ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: activating (auto-restart) (Result: exit-code) since Tue 2025-03-11 23:19:49 MST; 5s ago
Process: 22076 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 0 (code=exited, status=0/SUCCESS)
Process: 22099 ExecStart=/usr/bin/ceph-osd -f --cluster ${CLUSTER} --id 0 --setuser ceph --setgroup ceph (code=exited, status=1/FAILURE)
Main PID: 22099 (code=exited, status=1/FAILURE)
CPU: 104ms
Just tried this to no avail, seems like its a permisions error almost??