Thank you for accepting me to this board.
We need to upgrade our ProxMox but as a requirement we first need to update our ceph.
I'm following this guide to upgrade our Proxmox VE 6.4 Ceph Nautilus to Octopus: https://ainoniwa.net/pelican/2021-08-11a.html ( I know, it's in japanese but luckely there is google translate ) .
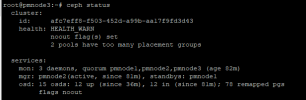
All went good until i come to the point that I have to "Upgrade all CephFS MDS daemons" (this is also the name of the chapter on that site) but there are no MDS services when I do a ceph status:


What can be wrong? How to solve this?
I've been looking for hours and it seems that I can't find the solution.
It's an environment that I have inherited from a engineer that has left the building. No documentation available.
Thank you for any help.
We need to upgrade our ProxMox but as a requirement we first need to update our ceph.
I'm following this guide to upgrade our Proxmox VE 6.4 Ceph Nautilus to Octopus: https://ainoniwa.net/pelican/2021-08-11a.html ( I know, it's in japanese but luckely there is google translate ) .
All went good until i come to the point that I have to "Upgrade all CephFS MDS daemons" (this is also the name of the chapter on that site) but there are no MDS services when I do a ceph status:
What can be wrong? How to solve this?
I've been looking for hours and it seems that I can't find the solution.
It's an environment that I have inherited from a engineer that has left the building. No documentation available.
Thank you for any help.
Attachments
Last edited:
