I'm trying to get to the bottom of a problem I just started having about middle of last week. I have a node that is almost two years old and it's worked flawlessly up until now. I did rebuild it about 4-5 months back as I wanted to the OS drive to be a mirrored ZFS pool, but nothing changed otherwise and I imported the original VM pool in as well. One of my VMs is an OpenVPN server. I noticed last week that I started having issues where every few minutes the connection would completely stall for about 5 seconds and then come back in. I wasn't disconnected from the server, but had no traffic moving in either direction. It happens regularly, but not like clockwork at exactly every 5 minutes. I noticed similar behavior when streaming in the internal network from a Windows gaming VM. I started trying to figure out if the problem was the node, the switch, etc. The logs at the time were so filled with the following error that I didn't notice the NIC error, but have since found it looking for it specifically.
Yesterday, before finding the NIC error, I finally put off clustering my three nodes. Upon doing so I've been able to see the node go offline for a few seconds and return. I've also activated a second physical NIC specifically for corosync and replication. This NIC also goes down. The two share a controller I'm sure so I'm wondering if that is starting to go bad or if I'm missing something. Here is the error from the log that I will regularly get.
I hadn't updated Proxmox prior to the issue arising. I then updated it last week, and again today, and it still persists through all of it. Is this likely a symptom of failing hardware or am I missing something bigger here? I have room to place a standalone network card in the server and transition to it. Do you think that might solve it? I'm open to any suggestions that I should be trying.
For now I've migrated my more critical VMs to the other nodes so they maintain proper functionality. As a note, no VMs or services ever complained about the outage. I even pinged the main server indefinitely from a Windows machine yesterday and while I felt I could visually see the hang, the ping never reported any drops or even longer times for response from the server for any packets. I'm at a loss and would really appreciate any help or insight. Thank you.
Code:
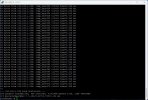
Jun 17 00:00:06 zeus kernel: kvm [97149]: ignored rdmsr: 0xc0010293 data 0x0
Jun 17 00:00:11 zeus kernel: kvm_msr_ignored_check: 104 callbacks suppressedYesterday, before finding the NIC error, I finally put off clustering my three nodes. Upon doing so I've been able to see the node go offline for a few seconds and return. I've also activated a second physical NIC specifically for corosync and replication. This NIC also goes down. The two share a controller I'm sure so I'm wondering if that is starting to go bad or if I'm missing something. Here is the error from the log that I will regularly get.
Code:
Jun 20 10:15:28 zeus kernel: ixgbe 0000:09:00.1 enp9s0f1: NIC Link is Down
Jun 20 10:15:28 zeus kernel: ixgbe 0000:09:00.0 enp9s0f0: NIC Link is Down
Jun 20 10:15:28 zeus kernel: vmbr0: port 1(enp9s0f0) entered disabled state
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] link: host: 3 link: 0 is down
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] link: host: 2 link: 0 is down
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] host: host: 3 (passive) best link: 0 (pri: 1)
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] host: host: 3 has no active links
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] host: host: 2 (passive) best link: 0 (pri: 1)
Jun 20 10:15:29 zeus corosync[201510]: [KNET ] host: host: 2 has no active links
Jun 20 10:15:30 zeus corosync[201510]: [TOTEM ] Token has not been received in 2737 ms
Jun 20 10:15:31 zeus corosync[201510]: [TOTEM ] A processor failed, forming new configuration: token timed out (3650ms), waiting 4380ms for consensus.
Jun 20 10:15:32 zeus kernel: ixgbe 0000:09:00.0 enp9s0f0: NIC Link is Up 10 Gbps, Flow Control: None
Jun 20 10:15:32 zeus kernel: vmbr0: port 1(enp9s0f0) entered blocking state
Jun 20 10:15:32 zeus kernel: vmbr0: port 1(enp9s0f0) entered forwarding state
Jun 20 10:15:32 zeus kernel: ixgbe 0000:09:00.1 enp9s0f1: NIC Link is Up 10 Gbps, Flow Control: NoneI hadn't updated Proxmox prior to the issue arising. I then updated it last week, and again today, and it still persists through all of it. Is this likely a symptom of failing hardware or am I missing something bigger here? I have room to place a standalone network card in the server and transition to it. Do you think that might solve it? I'm open to any suggestions that I should be trying.
For now I've migrated my more critical VMs to the other nodes so they maintain proper functionality. As a note, no VMs or services ever complained about the outage. I even pinged the main server indefinitely from a Windows machine yesterday and while I felt I could visually see the hang, the ping never reported any drops or even longer times for response from the server for any packets. I'm at a loss and would really appreciate any help or insight. Thank you.
Last edited: