Hardware Specification: The physical server network card model is the 82599ES 10-Gigabit SFI/SFP.
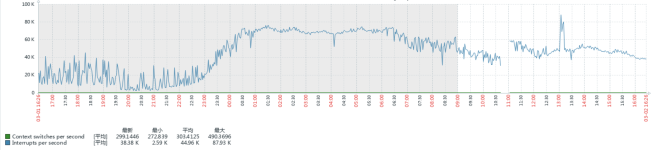
Problem Description: A virtual machine is running an LVS (Linux Virtual Server) service. When a single-source IP generates UDP traffic exceeding approximately 300 Mbps, packet loss begins to occur on the network interface. The actual business requires handling peak traffic rates of around 400 Mbps.
Requirement: Besides PCIe Passthrough (NIC Direct Pass-through), are there any other solutions that can ensure a single-source IP can receive UDP traffic exceeding 1 Gbps normally?
Traffic Characteristics: The UDP packets primarily consist of firewall logs. While individual packets are not large, the volume is high, with an estimated rate of 100,000 to 200,000 packets per second.
Baseline Observation: The same physical machine running VMware vSphere 6.7 with an identical virtual machine configuration appears to handle the 400 Mbps traffic load stably during testing.
")