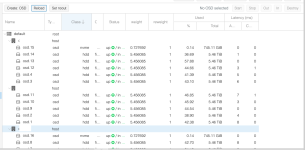
I followed https://ceph.com/community/new-luminous-crush-device-classes/
I add the rules and seems fine but not sure why the Ceph start replicated the HD data to the NVMe as well
I add the rules and seems fine but not sure why the Ceph start replicated the HD data to the NVMe as well
Code:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
device 9 osd.9 class hdd
device 10 osd.10 class hdd
device 11 osd.11 class hdd
device 12 osd.12 class hdd
device 13 osd.13 class hdd
device 14 osd.14 class hdd
device 15 osd.15 class nvme
device 16 osd.16 class nvme
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host de16 {
id -3 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
id -9 class nvme # do not change unnecessarily
# weight 28.008
alg straw2
hash 0 # rjenkins1
item osd.0 weight 5.456
item osd.5 weight 5.456
item osd.6 weight 5.456
item osd.8 weight 5.456
item osd.7 weight 5.456
item osd.16 weight 0.728
}
host de17 {
id -5 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
id -10 class nvme # do not change unnecessarily
# weight 27.280
alg straw2
hash 0 # rjenkins1
item osd.1 weight 5.456
item osd.2 weight 5.456
item osd.9 weight 5.456
item osd.10 weight 5.456
item osd.11 weight 5.456
}
host de18 {
id -7 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
id -11 class nvme # do not change unnecessarily
# weight 28.008
alg straw2
hash 0 # rjenkins1
item osd.12 weight 5.456
item osd.3 weight 5.456
item osd.4 weight 5.456
item osd.13 weight 5.456
item osd.14 weight 5.456
item osd.15 weight 0.728
}
root default {
id -1 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
id -12 class nvme # do not change unnecessarily
# weight 83.297
alg straw2
hash 0 # rjenkins1
item c16 weight 28.008
item c17 weight 27.280
item c18 weight 28.008
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule fast {
id 1
type replicated
min_size 1
max_size 10
step take default class nvme
step chooseleaf firstn 0 type host
step emit
}
rule ecpool {
id 2
type erasure
min_size 3
max_size 6
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class nvme
step chooseleaf indep 0 type host
step emit
}
# end crush map
Code:
root@xx:~# ceph -s
cluster:
id: 4cb23fa8-fab0-41d9-b334-02fe8dede3a8
health: HEALTH_WARN
226949/9796833 objects misplaced (2.317%)
Reduced data availability: 64 pgs inactive, 64 pgs incomplete
Degraded data redundancy: 102/9796833 objects degraded (0.001%), 1 pg degraded
services:
mon: 3 daemons, quorum c16,c17,c18
mgr: c16(active), standbys: c17, c18
osd: 17 osds: 17 up, 17 in; 34 remapped pgs
data:
pools: 3 pools, 640 pgs
objects: 3189k objects, 12358 GB
usage: 36630 GB used, 48665 GB / 85295 GB avail
pgs: 10.000% pgs not active
102/9796833 objects degraded (0.001%)
226949/9796833 objects misplaced (2.317%)
541 active+clean
64 creating+incomplete
31 active+remapped+backfill_wait
3 active+remapped+backfilling
1 active+recovery_wait+degraded
io:
client: 8786 kB/s rd, 38751 kB/s wr, 353 op/s rd, 429 op/s wr
recovery: 123 MB/s, 32 objects/s
root@xx:~#
Code:
root@xxx:~# pveversion --v
proxmox-ve: 5.2-2 (running kernel: 4.15.17-3-pve)
pve-manager: 5.2-6 (running version: 5.2-6/bcd5f008)
pve-kernel-4.15: 5.2-4
pve-kernel-4.15.18-1-pve: 4.15.18-17
pve-kernel-4.15.17-3-pve: 4.15.17-14
ceph: 12.2.7-pve1
corosync: 2.4.2-pve5
criu: 2.11.1-1~bpo90
glusterfs-client: 3.8.8-1
ksm-control-daemon: not correctly installed
libjs-extjs: 6.0.1-2
libpve-access-control: 5.0-8
libpve-apiclient-perl: 2.0-5
libpve-common-perl: 5.0-37
libpve-guest-common-perl: 2.0-17
libpve-http-server-perl: 2.0-9
libpve-storage-perl: 5.0-24
libqb0: 1.0.1-1
lvm2: 2.02.168-pve6
lxc-pve: 3.0.0-3
lxcfs: 3.0.0-1
novnc-pve: 1.0.0-2
proxmox-widget-toolkit: 1.0-19
pve-cluster: 5.0-29
pve-container: 2.0-24
pve-docs: 5.2-5
pve-firewall: 3.0-13
pve-firmware: 2.0-5
pve-ha-manager: 2.0-5
pve-i18n: 1.0-6
pve-libspice-server1: 0.12.8-3
pve-qemu-kvm: 2.11.2-1
pve-xtermjs: 1.0-5
qemu-server: 5.0-30
smartmontools: 6.5+svn4324-1
spiceterm: 3.0-5
vncterm: 1.5-3
zfsutils-linux: 0.7.9-pve1~bpo9