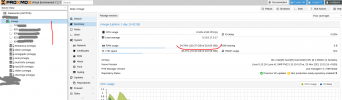
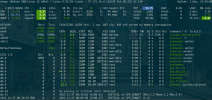
Memory leak, not freeing memory
83 threads of proxmox-backup-server
since host reboot, not a single VM has been started
only backup jobs
pve+pbs installed on btrfs raid1 (clean install 7.0 & 2.0 and updated to 7.1 & 2.1)
83 threads of proxmox-backup-server
since host reboot, not a single VM has been started
only backup jobs
pve+pbs installed on btrfs raid1 (clean install 7.0 & 2.0 and updated to 7.1 & 2.1)
Bash:
root@omega:~# pveversion -v
proxmox-ve: 7.1-1 (running kernel: 5.13.19-1-pve)
pve-manager: 7.1-7 (running version: 7.1-7/df5740ad)
pve-kernel-5.13: 7.1-4
pve-kernel-helper: 7.1-4
pve-kernel-5.13.19-1-pve: 5.13.19-3
ceph-fuse: 15.2.13-pve1
corosync: 3.1.5-pve2
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.22-pve2
libproxmox-acme-perl: 1.4.0
libproxmox-backup-qemu0: 1.2.0-1
libpve-access-control: 7.1-5
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.0-14
libpve-guest-common-perl: 4.0-3
libpve-http-server-perl: 4.0-4
libpve-network-perl: 0.6.2
libpve-storage-perl: 7.0-15
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 4.0.9-4
lxcfs: 4.0.8-pve2
novnc-pve: 1.2.0-3
proxmox-backup-client: 2.1.2-1
proxmox-backup-file-restore: 2.1.2-1
proxmox-mini-journalreader: 1.3-1
proxmox-widget-toolkit: 3.4-4
pve-cluster: 7.1-2
pve-container: 4.1-2
pve-docs: 7.1-2
pve-edk2-firmware: 3.20210831-2
pve-firewall: 4.2-5
pve-firmware: 3.3-3
pve-ha-manager: 3.3-1
pve-i18n: 2.6-2
pve-qemu-kvm: 6.1.0-2
pve-xtermjs: 4.12.0-1
qemu-server: 7.1-4
smartmontools: 7.2-1
spiceterm: 3.2-2
swtpm: 0.7.0~rc1+2
vncterm: 1.7-1
zfsutils-linux: 2.1.1-pve3Attachments
Last edited:



