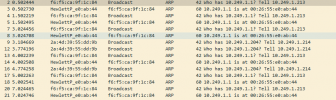
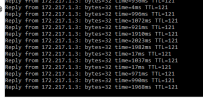
We also have problems with this.
For years.
We had an old 2008 R2 server that suddenly lost network, the network card showed it was still connected and everything but nothing could get through. Resetting the network card sometimes worked, and sometimes didn't.
A full reboot of the VM was the only thing that was guaranteed to work.
This could happen once a month, or once per week.
We recently setup two new servers running Windows Server 2019, a DC and an terminal server running some ERP software.
These are standard new Windows VM's with the E1000.
After a week we have had to restart the DC once and the terminal server we sometimes have to restart every 12 hours because of the connectivity issues.
We have had this weird problem for over two years now, and we always thought it was the old windows server os doing, but now this problem happens even more on new VM's running new up to date Windows Server 2019's.
The trend seems to be if the server is running software that does use a lot of network resources/connections like our ERP software. it will end up loosing network connectivity.
This seems to not have anything to do with network transfers since our sql server does not have this issue, and we transfer a lot data out of that VM every day.
We have updated Proxmox regularly for years and the issue just don't want to go away.
In retrospect I think this issue was introduced in Proxmox VE 5.
I will try the latest VirtIO (virtio-win-0.1.173) drivers and see if it gets any better after people get back from easter vacation.
For years.
We had an old 2008 R2 server that suddenly lost network, the network card showed it was still connected and everything but nothing could get through. Resetting the network card sometimes worked, and sometimes didn't.
A full reboot of the VM was the only thing that was guaranteed to work.
This could happen once a month, or once per week.
We recently setup two new servers running Windows Server 2019, a DC and an terminal server running some ERP software.
These are standard new Windows VM's with the E1000.
After a week we have had to restart the DC once and the terminal server we sometimes have to restart every 12 hours because of the connectivity issues.
We have had this weird problem for over two years now, and we always thought it was the old windows server os doing, but now this problem happens even more on new VM's running new up to date Windows Server 2019's.
The trend seems to be if the server is running software that does use a lot of network resources/connections like our ERP software. it will end up loosing network connectivity.
This seems to not have anything to do with network transfers since our sql server does not have this issue, and we transfer a lot data out of that VM every day.
We have updated Proxmox regularly for years and the issue just don't want to go away.
In retrospect I think this issue was introduced in Proxmox VE 5.
I will try the latest VirtIO (virtio-win-0.1.173) drivers and see if it gets any better after people get back from easter vacation.