We are facing a weird problem on our proxmox10 hypervisor. Let me briefly describe what you need to know:
The hypervisor is a KI host which runs a VM for a customer. It has a ASRock Rack B650D4U-2L2T/BCM mainbaord with a AMD Ryzen 9 7950X CPU and a NVIDIA RTX 4060 Ti is in the PCIe slot. It doesnt have the latest updates, its running pve-manager/7.4-17/513c62be.
But the host has not rebooted, otherwise these messages would be gone.
And thats what I did on both mondays, because I wasnt able to log in via SSH, I rebooted the host both times through BMC.
The screenshot shows several error messages related to I/O (Input/Output) operations on your Proxmox server, specifically for the device /dev/nvme0n1 and the logical block device dm-1. Here's a breakdown of the key issues:
NAME TYPE SIZE USED PRIO
/dev/dm-0 partition 8G 0B -2
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.15.126-1-pve] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 980 PRO 1TB
Serial Number: S5GXNX0W543648K
Firmware Version: 5B2QGXA7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 1,000,204,886,016 [1.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 6
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 1,000,204,886,016 [1.00 TB]
Namespace 1 Utilization: 651,848,630,272 [651 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 b531b2b2f6
Local Time is: Wed Jun 26 13:10:52 2024 CEST
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg
Maximum Data Transfer Size: 128 Pages
Warning Comp. Temp. Threshold: 82 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 8.49W - - 0 0 0 0 0 0
1 + 4.48W - - 1 1 1 1 0 200
2 + 3.18W - - 2 2 2 2 0 1000
3 - 0.0400W - - 3 3 3 3 2000 1200
4 - 0.0050W - - 4 4 4 4 500 9500
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 35 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 1%
Data Units Read: 5,883,153 [3.01 TB]
Data Units Written: 9,656,891 [4.94 TB]
Host Read Commands: 20,685,874
Host Write Commands: 261,994,118
Controller Busy Time: 1,980
Power Cycles: 21
Power On Hours: 517
Unsafe Shutdowns: 16
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 35 Celsius
Temperature Sensor 2: 37 Celsius
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged

ACTIVE '/dev/pve/swap' [8.00 GiB] inherit
ACTIVE '/dev/pve/root' [96.00 GiB] inherit
ACTIVE '/dev/pve/data' [794.30 GiB] inherit
ACTIVE '/dev/pve/vm-152-disk-0' [300.00 GiB] inherit
ACTIVE '/dev/pve/vm-150-disk-0' [300.00 GiB] inherit
root@proxmox10:~# vgscan
Found volume group "pve" using metadata type lvm2
root@proxmox10:~# pvscan
PV /dev/nvme0n1p3 VG pve lvm2 [<930.51 GiB / <16.00 GiB free]
Total: 1 [<930.51 GiB] / in use: 1 [<930.51 GiB] / in no VG: 0 [0 ]
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 894.3G 0 disk
├─sda1 8:1 0 894.2G 0 part
└─sda9 8:9 0 8M 0 part
sdb 8:16 0 894.3G 0 disk
├─sdb1 8:17 0 894.2G 0 part
└─sdb9 8:25 0 8M 0 part
sr0 11:0 1 1024M 0 rom
zd0 230:0 0 300G 0 disk
├─zd0p1 230:1 0 299G 0 part
├─zd0p2 230:2 0 1K 0 part
└─zd0p5 230:5 0 975M 0 part
zd16 230:16 0 300G 0 disk
├─zd16p1 230:17 0 299G 0 part
├─zd16p2 230:18 0 1K 0 part
└─zd16p5 230:21 0 975M 0 part
nvme0n1 259:0 0 931.5G 0 disk
├─nvme0n1p1 259:1 0 1007K 0 part
├─nvme0n1p2 259:2 0 1G 0 part /boot/efi
└─nvme0n1p3 259:3 0 930.5G 0 part
├─pve-swap 253:0 0 8G 0 lvm [SWAP]
├─pve-root 253:1 0 96G 0 lvm /
├─pve-data_tmeta 253:2 0 8.1G 0 lvm
│ └─pve-data-tpool 253:4 0 794.3G 0 lvm
│ ├─pve-data 253:5 0 794.3G 1 lvm
│ ├─pve-vm--152--disk--0 253:6 0 300G 0 lvm
│ └─pve-vm--150--disk--0 253:7 0 300G 0 lvm
└─pve-data_tdata 253:3 0 794.3G 0 lvm
└─pve-data-tpool 253:4 0 794.3G 0 lvm
├─pve-data 253:5 0 794.3G 1 lvm
├─pve-vm--152--disk--0 253:6 0 300G 0 lvm
└─pve-vm--150--disk--0 253:7 0 300G 0 lvm
root@proxmox10:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 31G 0 31G 0% /dev
tmpfs 6.2G 1.6M 6.2G 1% /run
/dev/mapper/pve-root 94G 4.3G 85G 5% /
tmpfs 31G 66M 31G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/nvme0n1p2 1022M 344K 1022M 1% /boot/efi
ZFS-Pool 514G 128K 514G 1% /ZFS-Pool
/dev/fuse 128M 152K 128M 1% /etc/pve
//172.16.16.7/Proxmox 7.0T 4.2T 2.9T 60% /mnt/pve/DasiCGN
//172.16.16.5/Proxmox 22T 8.4T 14T 39% /mnt/pve/DasiBN-Images
tmpfs 6.2G 0 6.2G 0% /run/user/0
root@proxmox10:~# pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p3 pve lvm2 a-- <930.51g <16.00g
root@proxmox10:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data pve twi-aotz-- 794.30g 44.86 1.56
root pve -wi-ao---- 96.00g
swap pve -wi-ao---- 8.00g
vm-150-disk-0 pve Vwi-a-tz-- 300.00g data 62.80
vm-152-disk-0 pve Vwi-a-tz-- 300.00g data 55.97
root@proxmox10:~# vgs
VG #PV #LV #SN Attr VSize VFree
pve 1 5 0 wz--n- <930.51g <16.00g
root@proxmox10:~# fdisk -l
Disk /dev/nvme0n1: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 980 PRO 1TB
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: FE38D51C-3E89-4BC1-8209-C14341F49F45
Device Start End Sectors Size Type
/dev/nvme0n1p1 34 2047 2014 1007K BIOS boot
/dev/nvme0n1p2 2048 2099199 2097152 1G EFI System
/dev/nvme0n1p3 2099200 1953525134 1951425935 930.5G Linux LVM
Disk /dev/sda: 894.25 GiB, 960197124096 bytes, 1875385008 sectors
Disk model: SAMSUNG MZ7LH960
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 834A8B3C-E50D-A54E-8A41-E1FD12ACE06B
Device Start End Sectors Size Type
/dev/sda1 2048 1875367935 1875365888 894.2G Solaris /usr & Apple ZFS
/dev/sda9 1875367936 1875384319 16384 8M Solaris reserved 1
Disk /dev/sdb: 894.25 GiB, 960197124096 bytes, 1875385008 sectors
Disk model: SAMSUNG MZ7LH960
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: A0DE28D3-EC9A-A048-B610-746FE257114E
Device Start End Sectors Size Type
/dev/sdb1 2048 1875367935 1875365888 894.2G Solaris /usr & Apple ZFS
/dev/sdb9 1875367936 1875384319 16384 8M Solaris reserved 1
Disk /dev/mapper/pve-swap: 8 GiB, 8589934592 bytes, 16777216 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-root: 96 GiB, 103079215104 bytes, 201326592 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-vm--152--disk--0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 65536 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/mapper/pve-vm--152--disk--0-part1 * 2048 627144703 627142656 299G 83 Linux
/dev/mapper/pve-vm--152--disk--0-part2 627146750 629143551 1996802 975M 5 Extended
/dev/mapper/pve-vm--152--disk--0-part5 627146752 629143551 1996800 975M 82 Linux swap
Partition 2 does not start on physical sector boundary.
Disk /dev/mapper/pve-vm--150--disk--0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 65536 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/mapper/pve-vm--150--disk--0-part1 * 2048 627144703 627142656 299G 83 Linux
/dev/mapper/pve-vm--150--disk--0-part2 627146750 629143551 1996802 975M 5 Extended
/dev/mapper/pve-vm--150--disk--0-part5 627146752 629143551 1996800 975M 82 Linux swap
Partition 2 does not start on physical sector boundary.
Disk /dev/zd0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 8192 bytes
I/O size (minimum/optimal): 8192 bytes / 8192 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/zd0p1 * 2048 627144703 627142656 299G 83 Linux
/dev/zd0p2 627146750 629143551 1996802 975M 5 Extended
/dev/zd0p5 627146752 629143551 1996800 975M 82 Linux swap / Solaris
Partition 2 does not start on physical sector boundary.
Disk /dev/zd16: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 8192 bytes
I/O size (minimum/optimal): 8192 bytes / 8192 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/zd16p1 * 2048 627144703 627142656 299G 83 Linux
/dev/zd16p2 627146750 629143551 1996802 975M 5 Extended
/dev/zd16p5 627146752 629143551 1996800 975M 82 Linux swap / Solaris
Partition 2 does not start on physical sector boundary.
The hypervisor is a KI host which runs a VM for a customer. It has a ASRock Rack B650D4U-2L2T/BCM mainbaord with a AMD Ryzen 9 7950X CPU and a NVIDIA RTX 4060 Ti is in the PCIe slot. It doesnt have the latest updates, its running pve-manager/7.4-17/513c62be.
The problem:
We did face the problem 2 times. The first time it must have happend around 09:00 on 09.06.24 and the second time was last weekend around 21:00 on 23.06.24. Quite interesting is, that both times were a sunday, where no one was working. Both times the hypervisor became unreachable and displayed many error messages on the remote screen in its BMC. (I do not have a screenshot right now, but I will paste as much details as I can in the logs section)But the host has not rebooted, otherwise these messages would be gone.
And thats what I did on both mondays, because I wasnt able to log in via SSH, I rebooted the host both times through BMC.
What did I do to solve this:
- Check SMART data, which looks fine for all drives (see Logs)
- I ran memtest86+, which gave me a PASS result, so the RAM seems to be not the reason
What did I did not do yet:
- I did not boot into a live linux and mount the drive to read the logs yet.
But I changed storage=persistent in /etc/systemd/journald.conf the second time this happened. - I did not ran fsck /dev/dm-1 yet. It shows /dev/mapper/pve-root is mounted. I guess I need to do this from live linux too.
- GPT suggested to recreate swap. I did not do this yet
(The commands to do this should bei guess?)Code:swapoff -a; mkswap /dev/dm-0; swapon /dev/dm-0; swapon --show
Logs:
BMC ERRORS
(I do not have a screenshot of the BMC errors, just this summary written by ChatGPT after posting the screenshot, but it does show which errors did show up)The screenshot shows several error messages related to I/O (Input/Output) operations on your Proxmox server, specifically for the device /dev/nvme0n1 and the logical block device dm-1. Here's a breakdown of the key issues:
- JBD2 Errors:
- JBD2: Error -5 detected when updating journal superblock for dm-1-8.
- JBD2 (Journaling Block Device v2) errors indicate problems with the journaling filesystem, which is critical for maintaining filesystem integrity.
- Buffer I/O Errors:
- Multiple Buffer I/O error on device dm-1, logical block ....
- These errors indicate that the system is unable to read/write data to the specified blocks on the device.
- EXT4 Filesystem Errors:
- EXT4-fs (dm-1): I/O error while writing superblock
- EXT4-fs (dm-1): ext4_journal_check_start: Detected aborted journal
- These errors are specific to the EXT4 filesystem, showing that it is encountering serious issues.
- Read/Write Errors:
- blk_update_request: I/O error, dev nvme0n1, sector ...
- These messages show that there are read/write errors occurring at specific sectors on the NVMe device.
- Swap Device Errors:
- Read-error on swap-device (253:0:345120)
- Errors on the swap device can cause the system to become unstable, as swap space is used for managing memory.
- Systemd Service Failures:
- systemd[1]: Failed to start System Logging Service.
- systemd[1]: pve-ha-crm.service: Can't convert PID files ...
- systemd[1]: boot-efi.mount: Failed to execute /bin/umount: Input/output error
- Systemd is reporting failures in starting services and mounting filesystems, likely due to underlying disk issues.
- General Input/Output Errors:
- Inode ... failed to read itable block
- These errors indicate that the filesystem cannot read necessary metadata.
swapon
root@proxmox10:~# swapon --showNAME TYPE SIZE USED PRIO
/dev/dm-0 partition 8G 0B -2
SMART values of nvme0n1
root@proxmox10:~# smartctl -a /dev/nvme0n1smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.15.126-1-pve] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 980 PRO 1TB
Serial Number: S5GXNX0W543648K
Firmware Version: 5B2QGXA7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 1,000,204,886,016 [1.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 6
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 1,000,204,886,016 [1.00 TB]
Namespace 1 Utilization: 651,848,630,272 [651 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 b531b2b2f6
Local Time is: Wed Jun 26 13:10:52 2024 CEST
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg
Maximum Data Transfer Size: 128 Pages
Warning Comp. Temp. Threshold: 82 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 8.49W - - 0 0 0 0 0 0
1 + 4.48W - - 1 1 1 1 0 200
2 + 3.18W - - 2 2 2 2 0 1000
3 - 0.0400W - - 3 3 3 3 2000 1200
4 - 0.0050W - - 4 4 4 4 500 9500
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 35 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 1%
Data Units Read: 5,883,153 [3.01 TB]
Data Units Written: 9,656,891 [4.94 TB]
Host Read Commands: 20,685,874
Host Write Commands: 261,994,118
Controller Busy Time: 1,980
Power Cycles: 21
Power On Hours: 517
Unsafe Shutdowns: 16
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 35 Celsius
Temperature Sensor 2: 37 Celsius
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
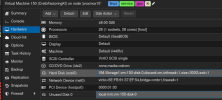
The KI VM Hardware page
lvscan/vgscan/pvscan
root@proxmox10:~# lvscanACTIVE '/dev/pve/swap' [8.00 GiB] inherit
ACTIVE '/dev/pve/root' [96.00 GiB] inherit
ACTIVE '/dev/pve/data' [794.30 GiB] inherit
ACTIVE '/dev/pve/vm-152-disk-0' [300.00 GiB] inherit
ACTIVE '/dev/pve/vm-150-disk-0' [300.00 GiB] inherit
root@proxmox10:~# vgscan
Found volume group "pve" using metadata type lvm2
root@proxmox10:~# pvscan
PV /dev/nvme0n1p3 VG pve lvm2 [<930.51 GiB / <16.00 GiB free]
Total: 1 [<930.51 GiB] / in use: 1 [<930.51 GiB] / in no VG: 0 [0 ]
Other commands regarding the disks
root@proxmox10:~# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 894.3G 0 disk
├─sda1 8:1 0 894.2G 0 part
└─sda9 8:9 0 8M 0 part
sdb 8:16 0 894.3G 0 disk
├─sdb1 8:17 0 894.2G 0 part
└─sdb9 8:25 0 8M 0 part
sr0 11:0 1 1024M 0 rom
zd0 230:0 0 300G 0 disk
├─zd0p1 230:1 0 299G 0 part
├─zd0p2 230:2 0 1K 0 part
└─zd0p5 230:5 0 975M 0 part
zd16 230:16 0 300G 0 disk
├─zd16p1 230:17 0 299G 0 part
├─zd16p2 230:18 0 1K 0 part
└─zd16p5 230:21 0 975M 0 part
nvme0n1 259:0 0 931.5G 0 disk
├─nvme0n1p1 259:1 0 1007K 0 part
├─nvme0n1p2 259:2 0 1G 0 part /boot/efi
└─nvme0n1p3 259:3 0 930.5G 0 part
├─pve-swap 253:0 0 8G 0 lvm [SWAP]
├─pve-root 253:1 0 96G 0 lvm /
├─pve-data_tmeta 253:2 0 8.1G 0 lvm
│ └─pve-data-tpool 253:4 0 794.3G 0 lvm
│ ├─pve-data 253:5 0 794.3G 1 lvm
│ ├─pve-vm--152--disk--0 253:6 0 300G 0 lvm
│ └─pve-vm--150--disk--0 253:7 0 300G 0 lvm
└─pve-data_tdata 253:3 0 794.3G 0 lvm
└─pve-data-tpool 253:4 0 794.3G 0 lvm
├─pve-data 253:5 0 794.3G 1 lvm
├─pve-vm--152--disk--0 253:6 0 300G 0 lvm
└─pve-vm--150--disk--0 253:7 0 300G 0 lvm
root@proxmox10:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 31G 0 31G 0% /dev
tmpfs 6.2G 1.6M 6.2G 1% /run
/dev/mapper/pve-root 94G 4.3G 85G 5% /
tmpfs 31G 66M 31G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/nvme0n1p2 1022M 344K 1022M 1% /boot/efi
ZFS-Pool 514G 128K 514G 1% /ZFS-Pool
/dev/fuse 128M 152K 128M 1% /etc/pve
//172.16.16.7/Proxmox 7.0T 4.2T 2.9T 60% /mnt/pve/DasiCGN
//172.16.16.5/Proxmox 22T 8.4T 14T 39% /mnt/pve/DasiBN-Images
tmpfs 6.2G 0 6.2G 0% /run/user/0
root@proxmox10:~# pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p3 pve lvm2 a-- <930.51g <16.00g
root@proxmox10:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data pve twi-aotz-- 794.30g 44.86 1.56
root pve -wi-ao---- 96.00g
swap pve -wi-ao---- 8.00g
vm-150-disk-0 pve Vwi-a-tz-- 300.00g data 62.80
vm-152-disk-0 pve Vwi-a-tz-- 300.00g data 55.97
root@proxmox10:~# vgs
VG #PV #LV #SN Attr VSize VFree
pve 1 5 0 wz--n- <930.51g <16.00g
root@proxmox10:~# fdisk -l
Disk /dev/nvme0n1: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 980 PRO 1TB
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: FE38D51C-3E89-4BC1-8209-C14341F49F45
Device Start End Sectors Size Type
/dev/nvme0n1p1 34 2047 2014 1007K BIOS boot
/dev/nvme0n1p2 2048 2099199 2097152 1G EFI System
/dev/nvme0n1p3 2099200 1953525134 1951425935 930.5G Linux LVM
Disk /dev/sda: 894.25 GiB, 960197124096 bytes, 1875385008 sectors
Disk model: SAMSUNG MZ7LH960
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 834A8B3C-E50D-A54E-8A41-E1FD12ACE06B
Device Start End Sectors Size Type
/dev/sda1 2048 1875367935 1875365888 894.2G Solaris /usr & Apple ZFS
/dev/sda9 1875367936 1875384319 16384 8M Solaris reserved 1
Disk /dev/sdb: 894.25 GiB, 960197124096 bytes, 1875385008 sectors
Disk model: SAMSUNG MZ7LH960
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: A0DE28D3-EC9A-A048-B610-746FE257114E
Device Start End Sectors Size Type
/dev/sdb1 2048 1875367935 1875365888 894.2G Solaris /usr & Apple ZFS
/dev/sdb9 1875367936 1875384319 16384 8M Solaris reserved 1
Disk /dev/mapper/pve-swap: 8 GiB, 8589934592 bytes, 16777216 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-root: 96 GiB, 103079215104 bytes, 201326592 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/mapper/pve-vm--152--disk--0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 65536 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/mapper/pve-vm--152--disk--0-part1 * 2048 627144703 627142656 299G 83 Linux
/dev/mapper/pve-vm--152--disk--0-part2 627146750 629143551 1996802 975M 5 Extended
/dev/mapper/pve-vm--152--disk--0-part5 627146752 629143551 1996800 975M 82 Linux swap
Partition 2 does not start on physical sector boundary.
Disk /dev/mapper/pve-vm--150--disk--0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 65536 bytes / 65536 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/mapper/pve-vm--150--disk--0-part1 * 2048 627144703 627142656 299G 83 Linux
/dev/mapper/pve-vm--150--disk--0-part2 627146750 629143551 1996802 975M 5 Extended
/dev/mapper/pve-vm--150--disk--0-part5 627146752 629143551 1996800 975M 82 Linux swap
Partition 2 does not start on physical sector boundary.
Disk /dev/zd0: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 8192 bytes
I/O size (minimum/optimal): 8192 bytes / 8192 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/zd0p1 * 2048 627144703 627142656 299G 83 Linux
/dev/zd0p2 627146750 629143551 1996802 975M 5 Extended
/dev/zd0p5 627146752 629143551 1996800 975M 82 Linux swap / Solaris
Partition 2 does not start on physical sector boundary.
Disk /dev/zd16: 300 GiB, 322122547200 bytes, 629145600 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 8192 bytes
I/O size (minimum/optimal): 8192 bytes / 8192 bytes
Disklabel type: dos
Disk identifier: 0xc4e81159
Device Boot Start End Sectors Size Id Type
/dev/zd16p1 * 2048 627144703 627142656 299G 83 Linux
/dev/zd16p2 627146750 629143551 1996802 975M 5 Extended
/dev/zd16p5 627146752 629143551 1996800 975M 82 Linux swap / Solaris
Partition 2 does not start on physical sector boundary.
Attachments
Last edited:

")
