Hallo,
Ich führe gerade einige Tests durch, wie sich Proxmox in größeren Setups verhält, wo im Worst case mehrere Aktionen zeitgleich oder mit wenigen Sekunden zeitlicher Versetzung ausgeführt werden.
Folgendes Beispiel, ich habe drei VMs, die im Abstand von wenigen Sekunden alle neu gebaut/ konfiguriert werden sollen.
Dieser Prozess besteht aus folgendem Ablauf:
- Existierende VM wird gestoppt und dann gelöscht
- Template wird geklont
- Setzen der HW Config
- Vergrößern der Disk
- Setzen Cloud Init Config
- Konfigurieren der Firewall
- Start der VM
Ausgeführt wird das über drei separate Background Worker, die eine simultane Ausführung zulassen.
Bei meinen tests bin ich reproduzierbar regelmäßig in Interrupt Probleme geraten.
Anbei ein paar weitere Screenshots.
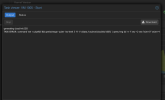
Beispielsweise kann ich regelmäßig folgende Probleme reproduzieren, wenn im letzten Schritt die VM gestartet werden soll:
Ähnliche Interrupt Probleme konnte ich aber auch bei anderen Aktionen auslösen, beispielsweise Stoppen einer VM oder teilweise beim setzen der Config.
Der Syslog zeigt leider keinerlei Auffälligkeiten.
Zwischen dem senden der einzelnen Requests habe ich stets überprüft, dass Proxmox keinen Lock mehr auf die VM hat und kein anderer Task zu dem Zeitpunkt noch läuft bevor der nächste Request gesendet wird.
Übersehe ich hier irgendwas?
Ich führe gerade einige Tests durch, wie sich Proxmox in größeren Setups verhält, wo im Worst case mehrere Aktionen zeitgleich oder mit wenigen Sekunden zeitlicher Versetzung ausgeführt werden.
Folgendes Beispiel, ich habe drei VMs, die im Abstand von wenigen Sekunden alle neu gebaut/ konfiguriert werden sollen.
Dieser Prozess besteht aus folgendem Ablauf:
- Existierende VM wird gestoppt und dann gelöscht
- Template wird geklont
- Setzen der HW Config
- Vergrößern der Disk
- Setzen Cloud Init Config
- Konfigurieren der Firewall
- Start der VM
Ausgeführt wird das über drei separate Background Worker, die eine simultane Ausführung zulassen.
Bei meinen tests bin ich reproduzierbar regelmäßig in Interrupt Probleme geraten.
Anbei ein paar weitere Screenshots.
Beispielsweise kann ich regelmäßig folgende Probleme reproduzieren, wenn im letzten Schritt die VM gestartet werden soll:
Code:
2023-11-27T18:53:07.059904+01:00 dev1 pvedaemon[28957]: command 'set -o pipefail && genisoimage -quiet -iso-level 3 -R -V cidata /run/pve/cloudinit/1003/ | qemu-img dd -n -f raw -O raw 'isize=0' 'osize=4194304' 'of=/dev/zvol/rpool/data/vm-1003-cloudinit'' failed: received interrupt
2023-11-27T18:53:07.066633+01:00 dev1 pvedaemon[24593]: <root@pam!api> end task UPID:dev1:0000711D:000477F2:6564D77D:qmstart:1003:root@pam!api: command 'set -o pipefail && genisoimage -quiet -iso-level 3 -R -V cidata /run/pve/cloudinit/1003/ | qemu-img dd -n -f raw -O raw 'isize=0' 'osize=4194304' 'of=/dev/zvol/rpool/data/vm-1003-cloudinit'' failed: received interrupt
Code:
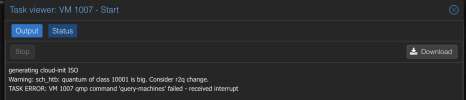
generating cloud-init ISO
Warning: sch_htb: quantum of class 10001 is big. Consider r2q change.
TASK ERROR: VM 1007 qmp command 'query-machines' failed - received interrupt
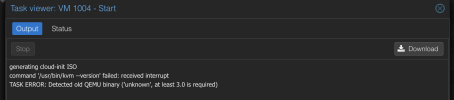
Code:
generating cloud-init ISO
command '/usr/bin/kvm --version' failed: received interrupt
TASK ERROR: Detected old QEMU binary ('unknown', at least 3.0 is required)Ähnliche Interrupt Probleme konnte ich aber auch bei anderen Aktionen auslösen, beispielsweise Stoppen einer VM oder teilweise beim setzen der Config.
Der Syslog zeigt leider keinerlei Auffälligkeiten.
Zwischen dem senden der einzelnen Requests habe ich stets überprüft, dass Proxmox keinen Lock mehr auf die VM hat und kein anderer Task zu dem Zeitpunkt noch läuft bevor der nächste Request gesendet wird.
Übersehe ich hier irgendwas?
Attachments
-
 Bildschirmfoto 2023-11-27 um 17.38.27.png96.8 KB · Views: 8
Bildschirmfoto 2023-11-27 um 17.38.27.png96.8 KB · Views: 8 -
 Bildschirmfoto 2023-11-27 um 17.38.29.png139.2 KB · Views: 8
Bildschirmfoto 2023-11-27 um 17.38.29.png139.2 KB · Views: 8 -
 Bildschirmfoto 2023-11-27 um 18.22.13.png64.5 KB · Views: 8
Bildschirmfoto 2023-11-27 um 18.22.13.png64.5 KB · Views: 8 -
 Bildschirmfoto 2023-11-27 um 18.37.40.png61.9 KB · Views: 7
Bildschirmfoto 2023-11-27 um 18.37.40.png61.9 KB · Views: 7 -
 Bildschirmfoto 2023-11-27 um 18.47.43.png34.1 KB · Views: 7
Bildschirmfoto 2023-11-27 um 18.47.43.png34.1 KB · Views: 7 -
 Bildschirmfoto 2023-11-27 um 19.13.12.png61.4 KB · Views: 7
Bildschirmfoto 2023-11-27 um 19.13.12.png61.4 KB · Views: 7
Last edited:
