Intel Nuc 13 Pro Thunderbolt Ring Network Ceph Cluster
- Thread starter l-koeln
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
D
Deleted member 205422
Guest
I did not go down the rabbithole, but I remember the PCIe related throughput was not up to 40, I cannot find my original source from where I found it, but Google now quickly gave me Anker explanation that:
"Data Transfer: Thunderbolt 3 has a PCIe data transfer speed of 16 Gbps, while Thunderbolt 4 supports a PCIe data transfer speed of 32 Gbps"
https://support.anker.com/s/article/What-is-the-difference-between-Thunderbolt-3-and-4
But it's all very strange, because iperf3 on 2 identical NUC11s reaches 18-19 in my own experience.
"Data Transfer: Thunderbolt 3 has a PCIe data transfer speed of 16 Gbps, while Thunderbolt 4 supports a PCIe data transfer speed of 32 Gbps"
https://support.anker.com/s/article/What-is-the-difference-between-Thunderbolt-3-and-4
But it's all very strange, because iperf3 on 2 identical NUC11s reaches 18-19 in my own experience.
remember some devices have more than one controller too, also I am not sure how many lanes it has access to, either way I know it’s a limitation of the chipset DMA controller on the 13th gen, hopefully will improve in future chipsets given the upcoming USB4 changes…. The TB code in next linux kernel is ready for those speeds…

So here are some performance tests from my ceph cluster.
I used the i3 NUC13 (NUC13ANHi3) in a three node full mesh setup, with the thunderbolt4 net as ceph network.
All tests are performed in a VM with 4 cores and 4GB of RAM.
The Ceph is built with one Samsung PM893 Datacenter SSD (3,84TB) in each node
For the fio test I used the following command:
My results are:
")
Here are some screenshots:
I used the i3 NUC13 (NUC13ANHi3) in a three node full mesh setup, with the thunderbolt4 net as ceph network.
All tests are performed in a VM with 4 cores and 4GB of RAM.
The Ceph is built with one Samsung PM893 Datacenter SSD (3,84TB) in each node
For the fio test I used the following command:
Code:
fio --filename=/dev/sdb --direct=1 --rw=<XXX> --bs=<YY>k --ioengine=libaio --iodepth=256 --runtime=120 --numjobs=4 --time_based --group_reporting --name=iops-test-job --eta-newline=1My results are:
- read 4k: 238k iop/s | 977MB/s
- write 4k: 53,4k iop/s | 219MB/s
- read 64k: 18,7k iop/s | 1228MB/s
- write 64k: 6985 iop/s | 458MB/s
- randread 4k: 63,4k iop/s | 260MB/s
- randwrite 4k: 12,4k iop/s | 50,8MB/s
- randrw 4k:
-> read: 9,9k iop/s | 40,9MB/s
-> write: 9,9k iop/s | 40,9MB/s
Here are some screenshots:
4k read

4k write

4k randrw

4k write
4k randrw
Last edited:
D
Deleted member 205422
Guest
So here are some performance tests from my ceph cluster.
I used the i3 NUC13 (NUC13ANHi3) in a three node full mesh setup, with the thunderbolt4 net as ceph network.
All tests are performed in a VM with 4 cores and 4GB of RAM.
The Ceph is built with one Samsung PM893 Datacenter SSD (3,84TB) in each node
For the fio test I used the following command:
Code:fio --filename=/dev/sdb --direct=1 --rw=<XXX> --bs=<YY>k --ioengine=libaio --iodepth=256 --runtime=120 --numjobs=4 --time_based --group_reporting --name=iops-test-job --eta-newline=1
My results are:
Not that bad for a cheap homelab ceph cluster
- read 4k: 238k iop/s | 977MB/s
- write 4k: 53,4k iop/s | 219MB/s
- read 64k: 18,7k iop/s | 1228MB/s
- write 64k: 6985 iop/s | 458MB/s
- randread 4k: 63,4k iop/s | 260MB/s
- randwrite 4k: 12,4k iop/s | 50,8MB/s
- randrw 4k:
-> read: 9,9k iop/s | 40,9MB/s
-> write: 9,9k iop/s | 40,9MB/s
The PM893s are the only storage in each NUC? Actually surprised at those read speeds, I always thought CEPH is not going to be any performant in a 3-node cluster. What was the CPU utilisation on the hosts during the test?
The PM893s are the only storage in each NUC? Actually surprised at those read speeds, I always thought CEPH is not going to be any performant in a 3-node cluster. What was the CPU utilisation on the hosts during the test?
I'm also kinda surprised ^^
I also installed a Transcend MTS430S SSD for the OS itself, so that I can use the pm893's for ceph only.
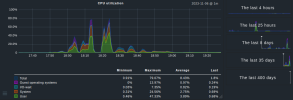
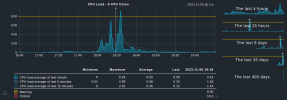
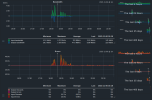
Sadly I didn't looked at the cpu usage during the tests, but I attached some screenshots from the monitoring during the test.
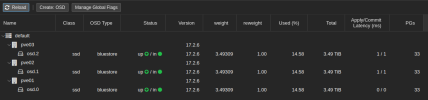
Edit: I also attached a screenshot from the OSD view.
Attachments
Last edited:
D
Deleted member 205422
Guest
I don't want to be creating any tasklist for you, in fact I thought I would just not use CEPH for my similar (more humble) NUC11s at all, in fact for anything 3-node, but I am glad someone tested it and published. The tests all ran 18:00-18:30, right? Anyhow, what crossed my mind was that it would be interesting to see how it performs in theI'm also kinda surprised ^^
I also installed a Transcend MTS430S SSD for the OS itself, so that I can use the pm893's for ceph only.
Sadly I didn't looked at the cpu usage during the tests, but I attached some screenshots from the monitoring during the test.
Edit: I also attached a screenshot from the OSD view.
 But don't take it as a challenge, I just wonder if that was a way to make good use of them.
But don't take it as a challenge, I just wonder if that was a way to make good use of them. Good point tbh[...] it would be interesting to see how it performs in theAdlerRaptor Lakes if the OSDs are pinned to the E-cores only.
One osd per node would mean 1 E Core for the osd, and the other for the VM's if they need it.
Maybe I will give that a try (even if the performance is already a way more then I expected and therefor already more than okay
), but for now I need to test the stability and recovery performance Edit:
correctThe tests all ran 18:00-18:30, right?
Last edited:
Yeah, was surprised at the speed with my Samsung 990 nvmes too. I was very pleased - I just did migrations from non-ceph to ceph storage and the write speed of the cluster was limited by the nvme not ceph…
Hey guys, just hope someone can help here. I followed the gist to the end and ended up with a 3 node cluster (NUC 13 pro) that is having a working connection after the 'vtysh -c "show openfabric topology"' was done the first time. I see 10.0.0.81, 82 and 83 there on any node.
If I reboot one machine the connection is gone (gracefully rebootet ofc), What am I doing wrong?
(gracefully rebootet ofc), What am I doing wrong?
This is the output on any node (ofc with different node names)
Here a screen after I did the vtysh stuff (ping f.e. working):

If I reboot one machine the connection is gone
(gracefully rebootet ofc), What am I doing wrong?This is the output on any node (ofc with different node names)
Bash:
root@pve03:~# dmesg | grep thunderbolt
[ 1.551640] ACPI: bus type thunderbolt registered
[ 2.673425] thunderbolt 0-0:1.1: new retimer found, vendor=0x8087 device=0x15ee
[ 3.804800] thunderbolt 1-0:1.1: new retimer found, vendor=0x8087 device=0x15ee
[ 7.778602] thunderbolt 0-1: new host found, vendor=0x8086 device=0x1
[ 7.778607] thunderbolt 0-1: Intel Corp. pve02
[ 7.782883] thunderbolt-net 0-1.0 en05: renamed from thunderbolt0
[ 9.123834] thunderbolt 1-1: new host found, vendor=0x8086 device=0x1
[ 9.123839] thunderbolt 1-1: Intel Corp. pve01
[ 9.125332] thunderbolt-net 1-1.0 en06: renamed from thunderbolt0Here a screen after I did the vtysh stuff (ping f.e. working):
Last edited:
Not sure, someone else reported this on the gist.
there are several possibilities:
1. you are not on an a real intel NUC 13th gen and have some wierd hw issue - i don;t think this is the case as you said nuc 13 pro and the output looks like it is from real nuc
2. you did something wrong with the modules file - but your kernel output indicates that not an issue
3. that leaves some weird issue with FRR - how long do you wait for it to converge, i have seen it take a couple of minutes at boot - are you waiting long enough?
4. did you implement IPv6 as well as IPv4 - try adding that and see if that works (i am dual stacked on FRR so maybe something i did in the v4 config is wriong for v4 only)
if those outputs were from when it was working can you post from a not working config?
please post the contents of your frr.conf files (and confirm to me you NEVER edited that file by hand for any reason, eg using nano on it)
please post the contents of your modules file
please post the contents of your interfaces file (i have a thesis my setting of static in the example may be wrong, my running rig uses manual)
please post the output of `cat /etc/sysctl.conf | grep forward`
what kernel version and frr version are you on?
there are several possibilities:
1. you are not on an a real intel NUC 13th gen and have some wierd hw issue - i don;t think this is the case as you said nuc 13 pro and the output looks like it is from real nuc
2. you did something wrong with the modules file - but your kernel output indicates that not an issue
3. that leaves some weird issue with FRR - how long do you wait for it to converge, i have seen it take a couple of minutes at boot - are you waiting long enough?
4. did you implement IPv6 as well as IPv4 - try adding that and see if that works (i am dual stacked on FRR so maybe something i did in the v4 config is wriong for v4 only)
if those outputs were from when it was working can you post from a not working config?
please post the contents of your frr.conf files (and confirm to me you NEVER edited that file by hand for any reason, eg using nano on it)
please post the contents of your modules file
please post the contents of your interfaces file (i have a thesis my setting of static in the example may be wrong, my running rig uses manual)
please post the output of `cat /etc/sysctl.conf | grep forward`
what kernel version and frr version are you on?
Last edited:
Not sure, someone else reported this on the gist.
there are several possibilities:
1. you are not on an a real intel NUC 13th gen and have some wierd hw issue - i don;t think this is the case as you said nuc 13 pro and the output looks like it is from real nuc
2. you did something wrong with the modules file - but your kernel output indicates that not an issue
3. that leaves some weird issue with FRR - how long do you wait for it to converge, i have seen it take a couple of minutes at boot - are you waiting long enough?
4. did you implement IPv6 as well as IPv4 - try adding that and see if that works (i am dual stacked on FRR so maybe something i did in the v4 config is wriong for v4 only)
if those outputs were from when it was working can you post from a not working config?
please post the contents of your frr.conf files (and confirm to me you NEVER edited that file by hand for any reason, eg using nano on it)
please post the contents of your modules file
please post the contents of your interfaces file (i have a thesis my setting of static in the example may be wrong, my running rig uses manual)
please post the output of `cat /etc/sysctl.conf | grep forward`
what kernel version and frr version are you on?
Hi Scyto, this is already my 2nd attempt to get it up and running. Last time I tried it with IPv6 now I try the IPv4 route. Here are all the answers to your questions, but first of all: thank you for your awesome work!
1. yes a real INTEL NUC not one from an other manufacturer (here the output of PVE WebGUI with Kernel etc):

2. output of my modules:
Bash:
root@pve01:~# cat /etc/modules
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be loaded
# at boot time, one per line. Lines beginning with "#" are ignored.
# Parameters can be specified after the module name.
thunderbolt
thunderbolt-net3. sometimes just a few seconds but after the system wasn't working as expected I came back a couple hours / or even a day later and it is the same state.
4. I can do it again, but didn't make any difference on my first attempt (yes I know I have then adjust /etc/sysctl.conf (maybe something for your guide: sysctl -p reads the file again without having to reboot)
frr.conf (node01)
Bash:
root@pve01:~# cat /etc/frr/frr.conf
frr version 8.5.2
frr defaults traditional
hostname pve01
log syslog informational
no ipv6 forwarding
service integrated-vtysh-config
!
interface en05
ip router openfabric 1
ipv6 router openfabric 1
exit
!
interface en06
ip router openfabric 1
ipv6 router openfabric 1
exit
!
interface lo
ip router openfabric 1
ipv6 router openfabric 1
openfabric passive
exit
!
router openfabric 1
net 49.0000.0000.0001.00
exit
!sysctl.conf
Bash:
root@pve01:~# cat /etc/sysctl.conf
#
# /etc/sysctl.conf - Configuration file for setting system variables
# See /etc/sysctl.d/ for additional system variables.
# See sysctl.conf (5) for information.
#
#kernel.domainname = example.com
# Uncomment the following to stop low-level messages on console
#kernel.printk = 3 4 1 3
###################################################################
# Functions previously found in netbase
#
# Uncomment the next two lines to enable Spoof protection (reverse-path filter)
# Turn on Source Address Verification in all interfaces to
# prevent some spoofing attacks
#net.ipv4.conf.default.rp_filter=1
#net.ipv4.conf.all.rp_filter=1
# Uncomment the next line to enable TCP/IP SYN cookies
# See http://lwn.net/Articles/277146/
# Note: This may impact IPv6 TCP sessions too
#net.ipv4.tcp_syncookies=1
# Uncomment the next line to enable packet forwarding for IPv4
net.ipv4.ip_forward=1
# Uncomment the next line to enable packet forwarding for IPv6
# Enabling this option disables Stateless Address Autoconfiguration
# based on Router Advertisements for this host
#net.ipv6.conf.all.forwarding=1last but not least the interfaces
Bash:
root@pve01:~# cat /etc/network/interfaces
auto lo
iface lo inet loopback
auto lo:0
iface lo:0 inet static
address 10.0.0.81/32
#auto lo:6
#iface lo:6 inet static
# address fc00::81/128
auto en05
iface en05 inet static
mtu 4000
#iface en05 inet6 static
# mtu 4000
auto en06
iface en06 inet static
mtu 4000
#iface en06 inet6 static
# mtu 4000
iface enp86s0 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.21.1/29
gateway 192.168.21.6
bridge-ports enp86s0
bridge-stp off
bridge-fd 0
source /etc/network/interfaces.d/*EDIT: forgot frr version
Bash:
root@pve01:~# vtysh
Hello, this is FRRouting (version 8.5.2).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
pve01# show version
FRRouting 8.5.2 (pve01) on Linux(6.5.11-7-pve).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
configured with:
'--build=x86_64-linux-gnu' '--prefix=/usr' '--includedir=${prefix}/include' '--mandir=${prefix}/share/man' '--infodir=${prefix}/share/info' '--sysconfdir=/etc' '--localstatedir=/var' '--disable-option-checking' '--disable-silent-rules' '--libdir=${prefix}/lib/x86_64-linux-gnu' '--runstatedir=/run' '--disable-maintainer-mode' '--localstatedir=/var/run/frr' '--sbindir=/usr/lib/frr' '--sysconfdir=/etc/frr' '--with-vtysh-pager=/usr/bin/pager' '--libdir=/usr/lib/x86_64-linux-gnu/frr' '--with-moduledir=/usr/lib/x86_64-linux-gnu/frr/modules' '--disable-dependency-tracking' '--disable-rpki' '--disable-scripting' '--enable-pim6d' '--with-libpam' '--enable-doc' '--enable-doc-html' '--enable-snmp' '--enable-fpm' '--disable-protobuf' '--disable-zeromq' '--enable-ospfapi' '--enable-bgp-vnc' '--enable-multipath=256' '--enable-user=frr' '--enable-group=frr' '--enable-vty-group=frrvty' '--enable-configfile-mask=0640' '--enable-logfile-mask=0640' 'build_alias=x86_64-linux-gnu' 'PYTHON=python3'EDIT2: because I was looking for the frr version I also noticed that there is a version 9.1 out there, trying with it now (install guideline here on proxmox without sudo installed) frrouting documentation:
Bash:
curl -s https://deb.frrouting.org/frr/keys.gpg | tee /usr/share/keyrings/frrouting.gpg > /dev/null
apt install -y lsb-release
FRRVER="frr-stable"
echo deb '[signed-by=/usr/share/keyrings/frrouting.gpg]' https://deb.frrouting.org/frr \
$(lsb_release -s -c) $FRRVER | tee -a /etc/apt/sources.list.d/frr.list
apt update
apt upgrade -y
Last edited:
something I noticed during my tests with the FRR configuration (maybe you could add this to your guide?)
I tryed just starting with a complete empty /etc/frr/frr.conf and restarted the service afterwards and checked if nothing was added by the daemon itself (it was still empty)
then I take a look what is the running config and the "default" part is already there and will be added by frr itself (no need to do this by ourselfes):
This part is not needed ok")
So I tryed it with just adding this to the config part:
it ended up with this:
yes you can add the IPv6 part ofc, that is just I try it with"stupid old" good old IPv4
EDIT: If you ask now if that fixed the issue that it is not working afterwards, ofc not xD the topology shows me all the other nodes but I can't ping anything (waited 5-10 minutes). But if I do a restart of frr again and wait about 30 seconds, then it works.
Maybe we can do a small script that is checking if ping is working and if not it will reboot frr automatically?
I came up with this, maybe a workaround, but we have to make sure that it is not restarting the service just because one of the devices isn't up and running, only if both other nodes are down it can be the case that frr isn't working as expected or was started tooo early.
example for node01 with IP 10.0.0.81
Ok after testing this seems to be no good solution as well, from time to time one ping fails and it is restarting the whole part again
EDIT2:
Ok I found a working solution with a friend
We just used the frr systemd service file to be run just 30 seconds later.
content of the frr.service file (this line was added: ExecStartPre=/bin/sleep 30)
after this we need to reload the daemon and test with a reboot
I tryed just starting with a complete empty /etc/frr/frr.conf and restarted the service afterwards and checked if nothing was added by the daemon itself (it was still empty)
then I take a look what is the running config and the "default" part is already there and will be added by frr itself (no need to do this by ourselfes):
Bash:
pve03# show running-config
Building configuration...
Current configuration:
!
frr version 9.1
frr defaults traditional
hostname pve03
no ipv6 forwarding
service integrated-vtysh-config
!This part is not needed ok
So I tryed it with just adding this to the config part:
Bash:
root@pve03:~# vtysh
Hello, this is FRRouting (version 9.1).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
pve03# config
pve03(config)# interface en05
pve03(config-if)# ip router openfabric 1
pve03(config-if)# exit
pve03(config)# !
pve03(config)# interface en06
pve03(config-if)# ip router openfabric 1
pve03(config-if)# exit
pve03(config)# !
pve03(config)# interface lo
pve03(config-if)# ip router openfabric 1
pve03(config-if)# openfabric passive
pve03(config-if)# exit
pve03(config)# !
pve03(config)# router openfabric 1
pve03(config-router)# net 49.0000.0000.0003.00
pve03(config-router)# exit
pve03(config)# !
pve03(config)# end
pve03# write memory
Note: this version of vtysh never writes vtysh.conf
Building Configuration...
Integrated configuration saved to /etc/frr/frr.conf
[OK]it ended up with this:
Bash:
root@pve03:~# cat /etc/frr/frr.conf
frr version 9.1
frr defaults traditional
hostname pve03
no ipv6 forwarding
service integrated-vtysh-config
!
interface en05
ip router openfabric 1
exit
!
interface en06
ip router openfabric 1
exit
!
interface lo
ip router openfabric 1
openfabric passive
exit
!
router openfabric 1
net 49.0000.0000.0003.00
exit
!yes you can add the IPv6 part ofc, that is just I try it with
EDIT: If you ask now if that fixed the issue that it is not working afterwards, ofc not xD the topology shows me all the other nodes but I can't ping anything (waited 5-10 minutes). But if I do a restart of frr again and wait about 30 seconds, then it works.
Maybe we can do a small script that is checking if ping is working and if not it will reboot frr automatically?
I came up with this, maybe a workaround, but we have to make sure that it is not restarting the service just because one of the devices isn't up and running, only if both other nodes are down it can be the case that frr isn't working as expected or was started tooo early.
example for node01 with IP 10.0.0.81
Bash:
#!/usr/bin/env bash
while true;
do
ping -c1 10.0.0.82 > /dev/null
ping1=$?
ping -c1 10.0.0.83 > /dev/null
ping2=$?
if [ ping1 != "0" ] && [ ping2 != "0" ]
then
# both other nodes not pingable
/usr/bin/systemctl restart frr.service
exit 0
else
# both other nodes are available
exit 0
fi
doneOk after testing this seems to be no good solution as well, from time to time one ping fails and it is restarting the whole part again
EDIT2:
Ok I found a working solution with a friend
We just used the frr systemd service file to be run just 30 seconds later.
Bash:
nano /lib/systemd/system/frr.servicecontent of the frr.service file (this line was added: ExecStartPre=/bin/sleep 30)
Bash:
[Unit]
Description=FRRouting
Documentation=https://frrouting.readthedocs.io/en/latest/setup.html
Wants=network.target
After=network-pre.target systemd-sysctl.service
Before=network.target
OnFailure=heartbeat-failed@%n
[Service]
ExecStartPre=/bin/sleep 30
Nice=-5
Type=forking
NotifyAccess=all
StartLimitInterval=3m
StartLimitBurst=3
TimeoutSec=2m
WatchdogSec=60s
RestartSec=5
Restart=always
LimitNOFILE=1024
PIDFile=/var/run/frr/watchfrr.pid
ExecStart=/usr/lib/frr/frrinit.sh start
ExecStop=/usr/lib/frr/frrinit.sh stop
ExecReload=/usr/lib/frr/frrinit.sh reload
[Install]
WantedBy=multi-user.targetafter this we need to reload the daemon and test with a reboot
Bash:
systemctl daemon-reload
reboot
Last edited:
Ok now I have the problem with CEPH :/
Installed the reef version as it is the latest one.
but it looks like this on WebGUI (you notice that there is no manager from pve01 that I used to create ceph as written in the guide)
network is up and running (I can ping, I can ssh to the other nodes over thunderbolt)

Creating the 2nd Manager from pve01 leads to timeout

Installed the reef version as it is the latest one.
Bash:
root@pve03:~# pveceph mon create --mon-address 10.0.0.83
monmaptool: monmap file /tmp/monmap
epoch 2
fsid bfe7330e-54a8-47e7-9fff-9a0fe263d43b
last_changed 2024-01-17T17:40:07.141415+0100
created 2024-01-17T17:39:53.161487+0100
min_mon_release 18 (reef)
election_strategy: 1
0: [v2:10.0.0.81:3300/0,v1:10.0.0.81:6789/0] mon.pve01
1: [v2:10.0.0.82:3300/0,v1:10.0.0.82:6789/0] mon.pve02
2: [v2:10.0.0.83:3300/0,v1:10.0.0.83:6789/0] mon.pve03
monmaptool: writing epoch 2 to /tmp/monmap (3 monitors)
Created symlink /etc/systemd/system/ceph-mon.target.wants/ceph-mon@pve03.service -> /lib/systemd/system/ceph-mon@.service.but it looks like this on WebGUI (you notice that there is no manager from pve01 that I used to create ceph as written in the guide)
network is up and running (I can ping, I can ssh to the other nodes over thunderbolt)
Creating the 2nd Manager from pve01 leads to timeout
problem solved with working ntp now
=> https://forum.proxmox.com/threads/c...te-2nd-3rd-monitor-manager.139569/post-625433
=> https://forum.proxmox.com/threads/c...te-2nd-3rd-monitor-manager.139569/post-625433
I don't think you need any of that, i think you missed my post about addingsomething I noticed during my tests with the FRR configuration (maybe you could add this to your guide?)
I tryed just starting with a complete empty /etc/frr/frr.conf and restarted the service afterwards and checked if nothing was added by the daemon itself (it was still empty)
then I take a look what is the running config and the "default" part is already there and will be added by frr itself (no need to do this by ourselfes):
Bash:pve03# show running-config Building configuration... Current configuration: ! frr version 9.1 frr defaults traditional hostname pve03 no ipv6 forwarding service integrated-vtysh-config !
This part is not needed ok
So I tryed it with just adding this to the config part:
Bash:root@pve03:~# vtysh Hello, this is FRRouting (version 9.1). Copyright 1996-2005 Kunihiro Ishiguro, et al. pve03# config pve03(config)# interface en05 pve03(config-if)# ip router openfabric 1 pve03(config-if)# exit pve03(config)# ! pve03(config)# interface en06 pve03(config-if)# ip router openfabric 1 pve03(config-if)# exit pve03(config)# ! pve03(config)# interface lo pve03(config-if)# ip router openfabric 1 pve03(config-if)# openfabric passive pve03(config-if)# exit pve03(config)# ! pve03(config)# router openfabric 1 pve03(config-router)# net 49.0000.0000.0003.00 pve03(config-router)# exit pve03(config)# ! pve03(config)# end pve03# write memory Note: this version of vtysh never writes vtysh.conf Building Configuration... Integrated configuration saved to /etc/frr/frr.conf [OK]
it ended up with this:
Bash:root@pve03:~# cat /etc/frr/frr.conf frr version 9.1 frr defaults traditional hostname pve03 no ipv6 forwarding service integrated-vtysh-config ! interface en05 ip router openfabric 1 exit ! interface en06 ip router openfabric 1 exit ! interface lo ip router openfabric 1 openfabric passive exit ! router openfabric 1 net 49.0000.0000.0003.00 exit !
yes you can add the IPv6 part ofc, that is just I try it with"stupid old"good old IPv4
EDIT: If you ask now if that fixed the issue that it is not working afterwards, ofc not xD the topology shows me all the other nodes but I can't ping anything (waited 5-10 minutes). But if I do a restart of frr again and wait about 30 seconds, then it works.
Maybe we can do a small script that is checking if ping is working and if not it will reboot frr automatically?
I came up with this, maybe a workaround, but we have to make sure that it is not restarting the service just because one of the devices isn't up and running, only if both other nodes are down it can be the case that frr isn't working as expected or was started tooo early.
example for node01 with IP 10.0.0.81
Bash:#!/usr/bin/env bash while true; do ping -c1 10.0.0.82 > /dev/null ping1=$? ping -c1 10.0.0.83 > /dev/null ping2=$? if [ ping1 != "0" ] && [ ping2 != "0" ] then # both other nodes not pingable /usr/bin/systemctl restart frr.service exit 0 else # both other nodes are available exit 0 fi done
Ok after testing this seems to be no good solution as well, from time to time one ping fails and it is restarting the whole part again
EDIT2:
Ok I found a working solution with a friend
We just used the frr systemd service file to be run just 30 seconds later.
Bash:nano /lib/systemd/system/frr.service
content of the frr.service file (this line was added: ExecStartPre=/bin/sleep 30)
Bash:[Unit] Description=FRRouting Documentation=https://frrouting.readthedocs.io/en/latest/setup.html Wants=network.target After=network-pre.target systemd-sysctl.service Before=network.target OnFailure=heartbeat-failed@%n [Service] ExecStartPre=/bin/sleep 30 Nice=-5 Type=forking NotifyAccess=all StartLimitInterval=3m StartLimitBurst=3 TimeoutSec=2m WatchdogSec=60s RestartSec=5 Restart=always LimitNOFILE=1024 PIDFile=/var/run/frr/watchfrr.pid ExecStart=/usr/lib/frr/frrinit.sh start ExecStop=/usr/lib/frr/frrinit.sh stop ExecReload=/usr/lib/frr/frrinit.sh reload [Install] WantedBy=multi-user.target
after this we need to reload the daemon and test with a reboot
Bash:systemctl daemon-reload reboot
post-up /usr/bin/systemctl restart frr.serviceat the very bottom of interfaces? This has the advantage of restarting the service in other contexts not just as boot.
Last edited:
I did add this but it didn't work for me, maybe it is working now because my ntp time is workingI don't think you need any of that, i think you missed my post about addingpost-up /usr/bin/systemctl restart frr.serviceat the very bottom of interfaces? This has the advantage of restarting the service in other contexts not just as boot.
I'm so grateful to all who documented their process of building a home lab cluster like this! I've just acquired 3 Intel NUC 13 Pro i7's for this exact purpose, and the information here, as well as the gist from @scyto will help immensely.
I've read through all of the threads and comments I could find so far. The last remaining big questions for me are these:
I've read through all of the threads and comments I could find so far. The last remaining big questions for me are these:
- Should I just download the latest PVE version, or should I be targeting a specific version from the past?
- Although I can't seem to locate the comment, I recall @scyto saying that people were describing problems that appeared to be introduced by later versions of PVE
- I'll be using backup/restore to move my CTs and VMs from another NUC running PVE 8.1.10 (kernel 6.5.13-3-pve) in case that needs to be considered
- After installation, should I update everything using the non-subscription repo, or do something more surgical?
- Considering the additional kernel patches required along the way (in the past at least):
- (1) Do I need to install some specific kernel post installation?
- (2) Do I need to compile any additional kernel patches?
- I recall reading somewhere that kernel 6.5 was causing issues at some point, and that someone recommended sticking with 6.2, but I'm not sure if that info is outdated now
- Which ceph repo is recommended at this point? Quincy or Reef?
yes NTP / same time on all nodes is important, as is DNS if you use names instead of IPs, when my cluster barfs (proxmox / docker / cepoh etc/ its usually time or DNS - to the point I am seriously considering to moving DNS to hardware...lolI did add this but it didn't work for me, maybe it is working now because my ntp time is working