Guten Morgen allerseits
Ich hab ein Problem, dass immer mal wieder auftritt, aber ich nicht eruieren kann, an was es liegt. Ich hab eine Vermutung, aber ich bräuchte Hilfe um zu bestätigen, dass es das ist.
Das Problem äusserst sich so, dass am Morgen irgendwann sich ein Host aufhängt beim Backupen (hier vermute ich meist ein LXC Container, ich habe 3 HV's und jeder von diesen 3-en ist immer mal wieder betroffen aber eben nicht konstant) und damit dann die ganze Maschine runterzieht. Diese Nacht war es der LXC Container welcher den DNS bereitstellt, was natürlich zu immensen Problemen geführt hat.
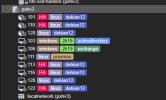
Im GUI sieht das dann wie im Screenshot aus - lustigerweise sind aber alle Maschinen bis auf die die sich aufgehängt hat immer noch komplett operativ, das heisst sie funktionieren problemlos. Heute war es der Container 101 (im Screenshot).
In welchem Log kann ich nachsehen bzw. nachvollziehen, was wohl das Problem war?
Ich hab ein Problem, dass immer mal wieder auftritt, aber ich nicht eruieren kann, an was es liegt. Ich hab eine Vermutung, aber ich bräuchte Hilfe um zu bestätigen, dass es das ist.
Das Problem äusserst sich so, dass am Morgen irgendwann sich ein Host aufhängt beim Backupen (hier vermute ich meist ein LXC Container, ich habe 3 HV's und jeder von diesen 3-en ist immer mal wieder betroffen aber eben nicht konstant) und damit dann die ganze Maschine runterzieht. Diese Nacht war es der LXC Container welcher den DNS bereitstellt, was natürlich zu immensen Problemen geführt hat.
Im GUI sieht das dann wie im Screenshot aus - lustigerweise sind aber alle Maschinen bis auf die die sich aufgehängt hat immer noch komplett operativ, das heisst sie funktionieren problemlos. Heute war es der Container 101 (im Screenshot).
In welchem Log kann ich nachsehen bzw. nachvollziehen, was wohl das Problem war?