Dear Proxmox-Community,
I'm relatively new to Proxmox and was working with VMware primarily before.
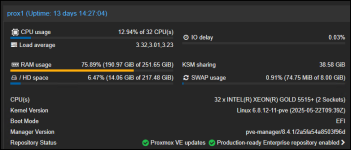
I have a new Host with the following Specs:
HPE ProLiant DL360 Gen11 SFF
2x Intel Xeon-Gold 5515+ (3.2Ghz/8-Core/165W)
8x HPE 32GB Dual Rank DDR5-4800 Registered Memory
1x HPE MR408i-o Gen11 SPDM Storage Controller
1x HPE 96W Smart Storage Battery with 145mm Cable
4x HPE 1.92TB SAS 12G Read Intensive SFF (2.5in) SSD
1x HPE NS204i-u Gen11 Hot Plug Boot Device
1x Broadcom BCM5719 1Gb 4-port BASE-T Adapter
1x HPE Ethernet 10Gb 2-port BASE-T BCM57416 Adapter
Proxmox is installed on the NS204i boot device. The SSDs are configured as a Raid 5 with the MR408i raid controller and with LVM-Thin which serves as the datastore.
VMs were migrated/imported from VMware which worked without problems.
My problem is that 1-2 times a day the raid controller seems to crash. During that time all VMs and the host stop responding and after a few minutes resume normal operation. Firmware of all hardware devices is up to date und also the Proxmox installation is up to date. I suspect that this happens when there is a spike in I/O operations.
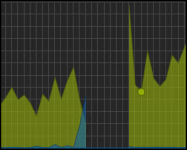
I attached a screenshot of the Proxmox information and of the CPU usage graph during such a crash. One can see the gap in the graph where the host hangs.
I also attached a log snippet from when the crash happens. iLO also logs th crash with the following event:
EVENT (31-Jul-2025 08:00): ControllerPreviousError (Slot=14, 0x7f833119) Redfish event from /redfish/v1/Systems/1/Storage/DE00B000/Controllers/0
Except from the crashes everything runs fast and normally.
Has anyone an idea what could cause this?
I would be grateful for any tips as I am out of ideas at the moment.
If I can provide more useful information, please let me know.
P.S.: Ditching the raid controller or configuring it with pass through for ZFS Raid is sadly not an option atm.
Best regards,
Alex
I'm relatively new to Proxmox and was working with VMware primarily before.
I have a new Host with the following Specs:
HPE ProLiant DL360 Gen11 SFF
2x Intel Xeon-Gold 5515+ (3.2Ghz/8-Core/165W)
8x HPE 32GB Dual Rank DDR5-4800 Registered Memory
1x HPE MR408i-o Gen11 SPDM Storage Controller
1x HPE 96W Smart Storage Battery with 145mm Cable
4x HPE 1.92TB SAS 12G Read Intensive SFF (2.5in) SSD
1x HPE NS204i-u Gen11 Hot Plug Boot Device
1x Broadcom BCM5719 1Gb 4-port BASE-T Adapter
1x HPE Ethernet 10Gb 2-port BASE-T BCM57416 Adapter
Proxmox is installed on the NS204i boot device. The SSDs are configured as a Raid 5 with the MR408i raid controller and with LVM-Thin which serves as the datastore.
VMs were migrated/imported from VMware which worked without problems.
My problem is that 1-2 times a day the raid controller seems to crash. During that time all VMs and the host stop responding and after a few minutes resume normal operation. Firmware of all hardware devices is up to date und also the Proxmox installation is up to date. I suspect that this happens when there is a spike in I/O operations.
I attached a screenshot of the Proxmox information and of the CPU usage graph during such a crash. One can see the gap in the graph where the host hangs.
I also attached a log snippet from when the crash happens. iLO also logs th crash with the following event:
EVENT (31-Jul-2025 08:00): ControllerPreviousError (Slot=14, 0x7f833119) Redfish event from /redfish/v1/Systems/1/Storage/DE00B000/Controllers/0
Except from the crashes everything runs fast and normally.
Has anyone an idea what could cause this?
I would be grateful for any tips as I am out of ideas at the moment.
If I can provide more useful information, please let me know.
P.S.: Ditching the raid controller or configuring it with pass through for ZFS Raid is sadly not an option atm.
Best regards,
Alex
Attachments
Last edited:

")