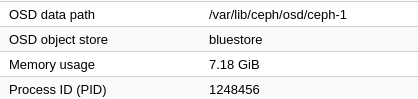
Hello Team,
We have recently create a mixed set up disk to create Ceph cluster, earlier we have 3 node cluster with 2TB of ssd on each node. Now we have added 4 tb of ssd to each node.
We observe huge memory spike per osd after adding 4tb of disk to cluster.
Please guide me how can i fix this issue and what is the standard procedure to make ceph stable.
Details about ceph cluster
ceph status
cluster:
id: 47061c54-d430-47c6-afa6-952da8e88877
health: HEALTH_OK
services:
mon: 3 daemons, quorum ge172,irage171,ge173 (age 6d)
mgr: ge172(active, since 4M), standbys: ge173, irage171
mds: 1/1 daemons up, 2 standby
osd: 6 osds: 6 up (since 26h), 6 in (since 26h)
data:
volumes: 1/1 healthy
pools: 4 pools, 209 pgs
objects: 141.50k objects, 547 GiB
usage: 1.6 TiB used, 15 TiB / 16 TiB avail
pgs: 209 active+clean
io:
client: 342 KiB/s wr, 0 op/s rd, 32 op/s wr
Ceph logs
tail -f /var/log/ceph/ceph.log
1706076060.8123205 mgr.irage172 (mgr.2464116) 6028054 : cluster [DBG] pgmap v6013783: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 2.4 MiB/s wr, 28 op/s
1706076062.8130574 mgr.irage172 (mgr.2464116) 6028055 : cluster [DBG] pgmap v6013784: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.8 MiB/s wr, 38 op/s
1706076064.8136814 mgr.irage172 (mgr.2464116) 6028056 : cluster [DBG] pgmap v6013785: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.7 MiB/s wr, 27 op/s
1706076066.8141751 mgr.irage172 (mgr.2464116) 6028057 : cluster [DBG] pgmap v6013786: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.5 MiB/s wr, 37 op/s
1706076068.8147433 mgr.irage172 (mgr.2464116) 6028058 : cluster [DBG] pgmap v6013787: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 133 KiB/s wr, 24 op/s
1706076070.8151488 mgr.irage172 (mgr.2464116) 6028059 : cluster [DBG] pgmap v6013788: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 112 KiB/s wr, 24 op/s
Pveversion -v
pveversion -v
proxmox-ve: 8.0.2 (running kernel: 6.2.16-8-pve)
pve-manager: 8.0.4 (running version: 8.0.4/d258a813cfa6b390)
proxmox-kernel-helper: 8.0.3
pve-kernel-6.2: 8.0.2
proxmox-kernel-6.2.16-8-pve: 6.2.16-8
proxmox-kernel-6.2: 6.2.16-8
pve-kernel-6.2.16-3-pve: 6.2.16-3
ceph: 17.2.6-pve1+3
ceph-fuse: 17.2.6-pve1+3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx2
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-3
libknet1: 1.25-pve1
libproxmox-acme-perl: 1.4.6
libproxmox-backup-qemu0: 1.4.0
libproxmox-rs-perl: 0.3.0
libpve-access-control: 8.0.3
libpve-apiclient-perl: 3.3.1
libpve-common-perl: 8.0.5
libpve-guest-common-perl: 5.0.3
libpve-http-server-perl: 5.0.3
libpve-rs-perl: 0.8.3
libpve-storage-perl: 8.0.1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 5.0.2-4
lxcfs: 5.0.3-pve3
novnc-pve: 1.4.0-2
proxmox-backup-client: 2.99.0-1
proxmox-backup-file-restore: 2.99.0-1
proxmox-kernel-helper: 8.0.3
proxmox-mail-forward: 0.1.1-1
proxmox-mini-journalreader: 1.4.0
proxmox-widget-toolkit: 4.0.5
pve-cluster: 8.0.1
pve-container: 5.0.3
pve-docs: 8.0.3
pve-edk2-firmware: 3.20230228-4
pve-firewall: 5.0.2
pve-firmware: 3.7-1
pve-ha-manager: 4.0.2
pve-i18n: 3.0.4
pve-qemu-kvm: 8.0.2-3
pve-xtermjs: 4.16.0-3
qemu-server: 8.0.6
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.1.12-pve1
We have recently create a mixed set up disk to create Ceph cluster, earlier we have 3 node cluster with 2TB of ssd on each node. Now we have added 4 tb of ssd to each node.
We observe huge memory spike per osd after adding 4tb of disk to cluster.
Please guide me how can i fix this issue and what is the standard procedure to make ceph stable.
Details about ceph cluster
ceph status
cluster:
id: 47061c54-d430-47c6-afa6-952da8e88877
health: HEALTH_OK
services:
mon: 3 daemons, quorum ge172,irage171,ge173 (age 6d)
mgr: ge172(active, since 4M), standbys: ge173, irage171
mds: 1/1 daemons up, 2 standby
osd: 6 osds: 6 up (since 26h), 6 in (since 26h)
data:
volumes: 1/1 healthy
pools: 4 pools, 209 pgs
objects: 141.50k objects, 547 GiB
usage: 1.6 TiB used, 15 TiB / 16 TiB avail
pgs: 209 active+clean
io:
client: 342 KiB/s wr, 0 op/s rd, 32 op/s wr
Ceph logs
tail -f /var/log/ceph/ceph.log
1706076060.8123205 mgr.irage172 (mgr.2464116) 6028054 : cluster [DBG] pgmap v6013783: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 2.4 MiB/s wr, 28 op/s
1706076062.8130574 mgr.irage172 (mgr.2464116) 6028055 : cluster [DBG] pgmap v6013784: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.8 MiB/s wr, 38 op/s
1706076064.8136814 mgr.irage172 (mgr.2464116) 6028056 : cluster [DBG] pgmap v6013785: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.7 MiB/s wr, 27 op/s
1706076066.8141751 mgr.irage172 (mgr.2464116) 6028057 : cluster [DBG] pgmap v6013786: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 1.5 MiB/s wr, 37 op/s
1706076068.8147433 mgr.irage172 (mgr.2464116) 6028058 : cluster [DBG] pgmap v6013787: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 341 B/s rd, 133 KiB/s wr, 24 op/s
1706076070.8151488 mgr.irage172 (mgr.2464116) 6028059 : cluster [DBG] pgmap v6013788: 209 pgs: 209 active+clean; 547 GiB data, 1.6 TiB used, 15 TiB / 16 TiB avail; 112 KiB/s wr, 24 op/s
Pveversion -v
pveversion -v
proxmox-ve: 8.0.2 (running kernel: 6.2.16-8-pve)
pve-manager: 8.0.4 (running version: 8.0.4/d258a813cfa6b390)
proxmox-kernel-helper: 8.0.3
pve-kernel-6.2: 8.0.2
proxmox-kernel-6.2.16-8-pve: 6.2.16-8
proxmox-kernel-6.2: 6.2.16-8
pve-kernel-6.2.16-3-pve: 6.2.16-3
ceph: 17.2.6-pve1+3
ceph-fuse: 17.2.6-pve1+3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx2
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-3
libknet1: 1.25-pve1
libproxmox-acme-perl: 1.4.6
libproxmox-backup-qemu0: 1.4.0
libproxmox-rs-perl: 0.3.0
libpve-access-control: 8.0.3
libpve-apiclient-perl: 3.3.1
libpve-common-perl: 8.0.5
libpve-guest-common-perl: 5.0.3
libpve-http-server-perl: 5.0.3
libpve-rs-perl: 0.8.3
libpve-storage-perl: 8.0.1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 5.0.2-4
lxcfs: 5.0.3-pve3
novnc-pve: 1.4.0-2
proxmox-backup-client: 2.99.0-1
proxmox-backup-file-restore: 2.99.0-1
proxmox-kernel-helper: 8.0.3
proxmox-mail-forward: 0.1.1-1
proxmox-mini-journalreader: 1.4.0
proxmox-widget-toolkit: 4.0.5
pve-cluster: 8.0.1
pve-container: 5.0.3
pve-docs: 8.0.3
pve-edk2-firmware: 3.20230228-4
pve-firewall: 5.0.2
pve-firmware: 3.7-1
pve-ha-manager: 4.0.2
pve-i18n: 3.0.4
pve-qemu-kvm: 8.0.2-3
pve-xtermjs: 4.16.0-3
qemu-server: 8.0.6
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.1.12-pve1