hello all
i'm facing a very strange problem, and cannot find the cause.
on 01/04 , i've migrate my old cluster (proxmox 7) to new hardware (two DELL R250, one T430, all with 32Go ram) with proxmox 8, all fine, all my vm run smoothly.
the two R250 have OS on a ssd, and use ZFS for storage, one node with two ssd in RAID O, the other with two HDD in RAID 0, with some's vm replicated (no HA) beetween theses nodes.
the T430 have OS on a ssd and storage on a harware raid5.
sunday 14/04, I started having problems with one vm (zimbra) on a R250, suddenly it started using 200% of the guest cpu (java process eat all cpu) and became extremely slow.
i suspect a zimbra bug, but after a long time to search for something wrong, nothing.
to make a test suggested on zimbra forum regarding zfs, i've finally make a backup of this vm for transfering it on another node without zfs.
first strange things, backup extremely slow, take 3 hours for finish, previous backup (one day before) take only less than 15 minutes.
after restore on the T430, all zimbra problem disapear!
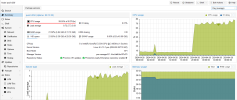
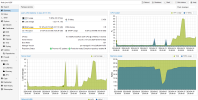
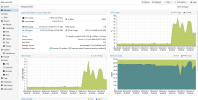
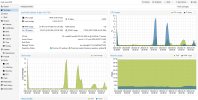
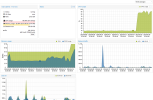
so, i've check my nodes, and i've discover than since two days (sunday 17h), all vm on the two nodes with zfs have cpu use growing! (but not enough to generate a problem, unlik with the zimbra server), see attached screens.
for example, a vm that previously used 5% cpu now uses 15%.
same on the second node.
and no replication job error
bur it's the first time i use zfs, so i'm outside of my comfort zone")
help?
i'm facing a very strange problem, and cannot find the cause.
on 01/04 , i've migrate my old cluster (proxmox 7) to new hardware (two DELL R250, one T430, all with 32Go ram) with proxmox 8, all fine, all my vm run smoothly.
the two R250 have OS on a ssd, and use ZFS for storage, one node with two ssd in RAID O, the other with two HDD in RAID 0, with some's vm replicated (no HA) beetween theses nodes.
the T430 have OS on a ssd and storage on a harware raid5.
sunday 14/04, I started having problems with one vm (zimbra) on a R250, suddenly it started using 200% of the guest cpu (java process eat all cpu) and became extremely slow.
i suspect a zimbra bug, but after a long time to search for something wrong, nothing.
to make a test suggested on zimbra forum regarding zfs, i've finally make a backup of this vm for transfering it on another node without zfs.
first strange things, backup extremely slow, take 3 hours for finish, previous backup (one day before) take only less than 15 minutes.
after restore on the T430, all zimbra problem disapear!
so, i've check my nodes, and i've discover than since two days (sunday 17h), all vm on the two nodes with zfs have cpu use growing! (but not enough to generate a problem, unlik with the zimbra server), see attached screens.
for example, a vm that previously used 5% cpu now uses 15%.
Code:
root@pve1-r250:~# zpool status
pool: zfs
state: ONLINE
scan: scrub repaired 0B in 00:47:10 with 0 errors on Sun Apr 14 01:11:11 2024
config:
NAME STATE READ WRITE CKSUM
zfs ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
errors: No known data errorssame on the second node.
and no replication job error
bur it's the first time i use zfs, so i'm outside of my comfort zone
help?
Code:
root@pve2-r250:~# pveversion
pve-manager/8.1.4/ec5affc9e41f1d79 (running kernel: 6.5.13-1-pve)Attachments
Last edited: