Hello folks,
We have a proxmox cluster running ver. 7.4 - not yet upgraded to 8.1 - will do shortly after we resolve the ceph issue.
Its a 4 node cluster with ceph on 3 nodes. with 6.4TB NVME * 2 for each host for ceph osd. means total of 6.4TB * 6 drives in the pool.
3 way replicated with 2 min. so total usable capacity is approx 12TB at 100% utilization.
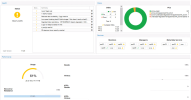
now our folks have not monitored the usage and it was at 95% i think and failure happened.
unfortunately both boot drives on one of the node failed and the 2 osd did not import and another osd on another node also failed which meant we were down to 3 OSD of the 6 having data.
anyway we replaced these and it started rebuilding but strangely we got osd full errors. we had 2 spare 6.4TB NVME drives available and we added them into 2 different hosts 1 each. so totally we have 8 OSD Now and it started rebuilding and rebalancing again only to get stuck at 97% and complaining of low disk space to backfill pg.
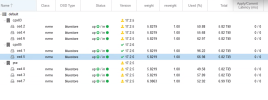
now if you see the attached screenshots you will see that in one node you have OSD1 and OSD5 and OSD1 kept writing data upto 95% but the other one is not writing beyond 66.98% - why is my question.
2nd question is that why is the space less. the same amount of data is there before failure and nothing got added so how is it finding shortage in space to accomodate the data even after adding 2 additional SSD
can somebody help please
We have a proxmox cluster running ver. 7.4 - not yet upgraded to 8.1 - will do shortly after we resolve the ceph issue.
Its a 4 node cluster with ceph on 3 nodes. with 6.4TB NVME * 2 for each host for ceph osd. means total of 6.4TB * 6 drives in the pool.
3 way replicated with 2 min. so total usable capacity is approx 12TB at 100% utilization.
now our folks have not monitored the usage and it was at 95% i think and failure happened.
unfortunately both boot drives on one of the node failed and the 2 osd did not import and another osd on another node also failed which meant we were down to 3 OSD of the 6 having data.
anyway we replaced these and it started rebuilding but strangely we got osd full errors. we had 2 spare 6.4TB NVME drives available and we added them into 2 different hosts 1 each. so totally we have 8 OSD Now and it started rebuilding and rebalancing again only to get stuck at 97% and complaining of low disk space to backfill pg.
now if you see the attached screenshots you will see that in one node you have OSD1 and OSD5 and OSD1 kept writing data upto 95% but the other one is not writing beyond 66.98% - why is my question.
2nd question is that why is the space less. the same amount of data is there before failure and nothing got added so how is it finding shortage in space to accomodate the data even after adding 2 additional SSD
can somebody help please