Hi everyone, I installed a bare metal PBS on a dual 4110 with 128GB of ram and SSD.
I tried all possible configurations switching from ZFS to any configuration, in extreme I even created a DS with 1 single SSD. I'm on a full 10GB network, the proxmox servers have 2 10gb and the PBS 2 10gb with MTU and network speed tested withiperf.
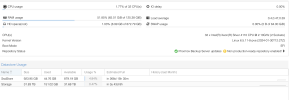
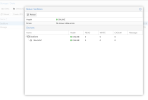
I attach a screenshot of the PBS configuration and the compression used, in no way can I reach a backup speed higher than 90/100 MB/s. Where can I check and understand where the bottleneck is? Does PBS have 1GB limits somewhere?
I tried all possible configurations switching from ZFS to any configuration, in extreme I even created a DS with 1 single SSD. I'm on a full 10GB network, the proxmox servers have 2 10gb and the PBS 2 10gb with MTU and network speed tested withiperf.
I attach a screenshot of the PBS configuration and the compression used, in no way can I reach a backup speed higher than 90/100 MB/s. Where can I check and understand where the bottleneck is? Does PBS have 1GB limits somewhere?








")