Hello, I've got a bit of an issue. I'm running Proxmox 8.3 on a MinisForum NAB9.
Power went out the other day but I didn't notice any issues when it came back and turned the machine back on.
That was unitl I tried to make a backup of one of my VMs (VM 100 - it's a Windows 10 LTSC machine) and it keeps giving me the error in the title.
On my setup, backups are supposed to be stored on local-lvm, but I also have a NAS where I could store them. Tried both options but it doesn't seem to make any difference.
Tried different compression methods but also doesn't seem to make any difference. It's the only VM that refuses to backup (it was on at the time of the power outage).
I've tried backing up other VMs and CTs and they backup just fine, that one seems to be the only one affected.
The way I see it, given the info I've gathered it seems to be related to some bad sectors and I'm thinking that a fsck would probably solve the issue, the problem is that it doesn't seem to be that straightforward doing it on Proxmox and frankly I'm completely lost at this point. Some help would be greatly appreciated as I use that machine for some work related stuff and I'd like to be able to back it up just in case. I'd like to know how I could run something like fsck or some other tool to scan and repair the drive where my VM's data resides. I'm not a Linux expert by any means, especially when it comes to Proxmox, otherwise I wouldn't be here.
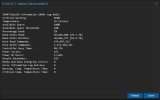
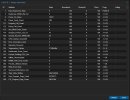
I'll provide some relevant info down below. I'll also attach some screenshots of S.M.A.R.T data of both my root drive (nvme where pve-root and local-lvm reside) and also another SSD I have on the system where I keep backups, ISOs and CT Templates.
Backup job log :
Journalctl during backup job :
Package versions :
Power went out the other day but I didn't notice any issues when it came back and turned the machine back on.
That was unitl I tried to make a backup of one of my VMs (VM 100 - it's a Windows 10 LTSC machine) and it keeps giving me the error in the title.
On my setup, backups are supposed to be stored on local-lvm, but I also have a NAS where I could store them. Tried both options but it doesn't seem to make any difference.
Tried different compression methods but also doesn't seem to make any difference. It's the only VM that refuses to backup (it was on at the time of the power outage).
I've tried backing up other VMs and CTs and they backup just fine, that one seems to be the only one affected.
The way I see it, given the info I've gathered it seems to be related to some bad sectors and I'm thinking that a fsck would probably solve the issue, the problem is that it doesn't seem to be that straightforward doing it on Proxmox and frankly I'm completely lost at this point. Some help would be greatly appreciated as I use that machine for some work related stuff and I'd like to be able to back it up just in case. I'd like to know how I could run something like fsck or some other tool to scan and repair the drive where my VM's data resides. I'm not a Linux expert by any means, especially when it comes to Proxmox, otherwise I wouldn't be here.
I'll provide some relevant info down below. I'll also attach some screenshots of S.M.A.R.T data of both my root drive (nvme where pve-root and local-lvm reside) and also another SSD I have on the system where I keep backups, ISOs and CT Templates.
Backup job log :
Code:
INFO: starting new backup job: vzdump 100 --protected 1 --notification-mode auto --remove 0 --node pve --compress zstd --notes-template '{{guestname}}' --storage local-storage --mode stop
INFO: Starting Backup of VM 100 (qemu)
INFO: Backup started at 2025-02-17 19:00:46
INFO: status = stopped
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: VM Name: Win10-LTSC
INFO: include disk 'scsi0' 'local-lvm:vm-100-disk-1' 250G
INFO: include disk 'efidisk0' 'local-lvm:vm-100-disk-0' 4M
INFO: creating vzdump archive '/mnt/pve/local-storage/dump/vzdump-qemu-100-2025_02_17-19_00_46.vma.zst'
INFO: starting kvm to execute backup task
INFO: started backup task '2ab191a2-2fa3-437b-a705-dbb23cf337ce'
INFO: 0% (178.0 MiB of 250.0 GiB) in 1s, read: 178.0 MiB/s, write: 88.1 MiB/s
ERROR: job failed with err -5 - Input/output error
INFO: aborting backup job
INFO: stopping kvm after backup task
ERROR: Backup of VM 100 failed - job failed with err -5 - Input/output error
INFO: Failed at 2025-02-17 19:00:49
INFO: Backup job finished with errors
TASK ERROR: job errorsJournalctl during backup job :
Code:
Feb 17 19:00:46 pve pvedaemon[2344]: INFO: starting new backup job: vzdump 100 --protected 1 --notification-mode auto --remove 0 --node pve --compress zstd --notes-template '{{guestname}}' --storage local-storage --mode stop
Feb 17 19:00:46 pve pvedaemon[2344]: INFO: Starting Backup of VM 100 (qemu)
Feb 17 19:00:46 pve systemd[1]: Created slice qemu.slice - Slice /qemu.
Feb 17 19:00:46 pve systemd[1]: Started 100.scope.
Feb 17 19:00:47 pve kernel: tap100i0: entered promiscuous mode
Feb 17 19:00:47 pve kernel: vmbr0: port 2(fwpr100p0) entered blocking state
Feb 17 19:00:47 pve kernel: vmbr0: port 2(fwpr100p0) entered disabled state
Feb 17 19:00:47 pve kernel: fwpr100p0: entered allmulticast mode
Feb 17 19:00:47 pve kernel: fwpr100p0: entered promiscuous mode
Feb 17 19:00:47 pve kernel: vmbr0: port 2(fwpr100p0) entered blocking state
Feb 17 19:00:47 pve kernel: vmbr0: port 2(fwpr100p0) entered forwarding state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 1(fwln100i0) entered blocking state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 1(fwln100i0) entered disabled state
Feb 17 19:00:47 pve kernel: fwln100i0: entered allmulticast mode
Feb 17 19:00:47 pve kernel: fwln100i0: entered promiscuous mode
Feb 17 19:00:47 pve kernel: fwbr100i0: port 1(fwln100i0) entered blocking state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 1(fwln100i0) entered forwarding state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 2(tap100i0) entered blocking state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 2(tap100i0) entered disabled state
Feb 17 19:00:47 pve kernel: tap100i0: entered allmulticast mode
Feb 17 19:00:47 pve kernel: fwbr100i0: port 2(tap100i0) entered blocking state
Feb 17 19:00:47 pve kernel: fwbr100i0: port 2(tap100i0) entered forwarding state
Feb 17 19:00:47 pve pvedaemon[2344]: VM 100 started with PID 2364.
Feb 17 19:00:47 pve kernel: nvme0n1: I/O Cmd(0x2) @ LBA 938005504, 256 blocks, I/O Error (sct 0x2 / sc 0x81)
Feb 17 19:00:47 pve kernel: critical medium error, dev nvme0n1, sector 938005504 op 0x0:(READ) flags 0x80700 phys_seg 3 prio class 2
Feb 17 19:00:47 pve kernel: nvme0n1: I/O Cmd(0x2) @ LBA 938005544, 8 blocks, I/O Error (sct 0x2 / sc 0x81)
Feb 17 19:00:47 pve kernel: critical medium error, dev nvme0n1, sector 938005544 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2
Feb 17 19:00:47 pve kernel: Buffer I/O error on dev dm-10, logical block 40997, async page read
Feb 17 19:00:47 pve kernel: nvme0n1: I/O Cmd(0x2) @ LBA 938005544, 8 blocks, I/O Error (sct 0x2 / sc 0x81)
Feb 17 19:00:47 pve kernel: critical medium error, dev nvme0n1, sector 938005544 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2
Feb 17 19:00:47 pve kernel: Buffer I/O error on dev dm-10, logical block 40997, async page read
Feb 17 19:00:48 pve kernel: tap100i0: left allmulticast mode
Feb 17 19:00:48 pve kernel: fwbr100i0: port 2(tap100i0) entered disabled state
Feb 17 19:00:48 pve kernel: fwbr100i0: port 1(fwln100i0) entered disabled state
Feb 17 19:00:48 pve kernel: vmbr0: port 2(fwpr100p0) entered disabled state
Feb 17 19:00:48 pve kernel: fwln100i0 (unregistering): left allmulticast mode
Feb 17 19:00:48 pve kernel: fwln100i0 (unregistering): left promiscuous mode
Feb 17 19:00:48 pve kernel: fwbr100i0: port 1(fwln100i0) entered disabled state
Feb 17 19:00:48 pve kernel: fwpr100p0 (unregistering): left allmulticast mode
Feb 17 19:00:48 pve kernel: fwpr100p0 (unregistering): left promiscuous mode
Feb 17 19:00:48 pve kernel: vmbr0: port 2(fwpr100p0) entered disabled state
Feb 17 19:00:48 pve qmeventd[941]: read: Connection reset by peer
Feb 17 19:00:48 pve pvedaemon[1316]: VM 100 qmp command failed - unable to open monitor socket
Feb 17 19:00:48 pve systemd[1]: 100.scope: Deactivated successfully.
Feb 17 19:00:48 pve qmeventd[2527]: Starting cleanup for 100
Feb 17 19:00:48 pve qmeventd[2527]: trying to acquire lock...
Feb 17 19:00:49 pve qmeventd[2527]: OK
Feb 17 19:00:49 pve qmeventd[2527]: Finished cleanup for 100
Feb 17 19:00:49 pve pvedaemon[2344]: ERROR: Backup of VM 100 failed - job failed with err -5 - Input/output error
Feb 17 19:00:49 pve pvedaemon[2344]: INFO: Backup job finished with errors
Feb 17 19:00:49 pve perl[2344]: notified via target `mail-to-root`
Feb 17 19:00:49 pve pvedaemon[2344]: job errorsPackage versions :
Code:
proxmox-ve: 8.3.0 (running kernel: 6.8.12-8-pve)
pve-manager: 8.3.3 (running version: 8.3.3/f157a38b211595d6)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-8
proxmox-kernel-6.8.12-8-pve-signed: 6.8.12-8
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
ceph-fuse: 17.2.7-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2+deb12u1
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx11
intel-microcode: 3.20241112.1~deb12u1
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.5.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.2.0
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.3
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.4
pve-cluster: 8.0.10
pve-container: 5.2.3
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-3
pve-ha-manager: 4.0.6
pve-i18n: 3.3.3
pve-qemu-kvm: 9.0.2-5
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.7
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.7-pve1