[SOLVED] Edit .members file
- Thread starter herseitan
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Hi,
Not directly, it's a virtual file that shows the current cluster member, which is derived from which nodes you joined the cluster and if the cluster is healthy. So you can indirectly change its content by joining or making nodes leave.
https://pve.proxmox.com/pve-docs/chapter-pmxcfs.html#_special_status_files_for_debugging_json
https://pve.proxmox.com/pve-docs/chapter-pvecm.html#pvecm_join_node_to_cluster
So, why would you want to edit that, i.e., what's your actual issue?
Not directly, it's a virtual file that shows the current cluster member, which is derived from which nodes you joined the cluster and if the cluster is healthy. So you can indirectly change its content by joining or making nodes leave.
https://pve.proxmox.com/pve-docs/chapter-pmxcfs.html#_special_status_files_for_debugging_json
https://pve.proxmox.com/pve-docs/chapter-pvecm.html#pvecm_join_node_to_cluster
So, why would you want to edit that, i.e., what's your actual issue?
Last edited:
Thanks for your reply t.lamprecht.
I have a "Network" issue with my cluster, when i created the cluster I select the Cluster Network with an interface in a range 192.X.X.X, both nodes has been joined to the cluster (apparently) fine but for some reason that I dont know one of the nodes takes a network interface with another range.
When I trying to move a VM from host "56" to host "52" I dont have any issue, work perfect.
But when i tried to move from "52" to "56" i have an error caused by the "different" network
TASK ERROR: command '/usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=56' root@38.X.X.X pvecm mtunnel -migration_network 192.168.X.X/24 -get_migration_ip' failed: exit code 255
So ".members" file have the wrong IP address, that's why I want to edit that file.
Thanks again for your reply.
Regards !!
I have a "Network" issue with my cluster, when i created the cluster I select the Cluster Network with an interface in a range 192.X.X.X, both nodes has been joined to the cluster (apparently) fine but for some reason that I dont know one of the nodes takes a network interface with another range.
When I trying to move a VM from host "56" to host "52" I dont have any issue, work perfect.
But when i tried to move from "52" to "56" i have an error caused by the "different" network
TASK ERROR: command '/usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=56' root@38.X.X.X pvecm mtunnel -migration_network 192.168.X.X/24 -get_migration_ip' failed: exit code 255
So ".members" file have the wrong IP address, that's why I want to edit that file.
Thanks again for your reply.
Regards !!
Attachments
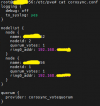
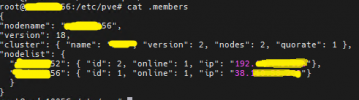
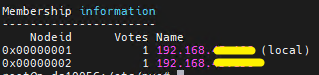
The IP shown in
So, if you edit that (directly or via the API) to its IP from the 192.168.x.y/z network and reboot the node you should be good again.
For the migration network specific issue you can also override the migration network in the Web UI under Datacenter -> Options -> Migration Settings, if you set the 192.168.x.y/z network explicitly there, the nodes should avoid the autodetection, and it should work again.
Correcting the IP resolution of the nodename makes sense nonetheless, as if the node isn't reachable by the other node via that (or takes an inefficient route) you'll always have trouble for some action in a cluster.
.members is the one the node name resolves too, and if you don't have an internal DNS infrastructure this is most likely coming from /etc/hosts on the affected node itself.So, if you edit that (directly or via the API) to its IP from the 192.168.x.y/z network and reboot the node you should be good again.
For the migration network specific issue you can also override the migration network in the Web UI under Datacenter -> Options -> Migration Settings, if you set the 192.168.x.y/z network explicitly there, the nodes should avoid the autodetection, and it should work again.
Correcting the IP resolution of the nodename makes sense nonetheless, as if the node isn't reachable by the other node via that (or takes an inefficient route) you'll always have trouble for some action in a cluster.
Understood, it seems logical to meThe IP shown in.membersis the one the node name resolves too, and if you don't have an internal DNS infrastructure this is most likely coming from/etc/hostson the affected node itself.
So, if you edit that (directly or via the API) to its IP from the 192.168.x.y/z network and reboot the node you should be good again.
")
I will try and i will return with the feedback.
Thanks a lot for your help !!
")
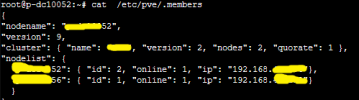
Great that you got it to work! As thread creator you could set the "Solved" prefix for this thread, using the
Edit Thread button above your initial post at the right.I recently ran into the same issue (Proxmox was guessing the wrong IP address for my nodes, which caused
I didn't want to reboot my nodes; but it looks like merely restarting pve-cluster was enough (
Connection error 595: No route to host errors in the web UI). I also fixed it by editing /etc/hosts.I didn't want to reboot my nodes; but it looks like merely restarting pve-cluster was enough (
systemctl restart pve-cluster), so I'm leaving that comment in case that helps anyone else.I can echo this, sort of.
I had a cluster configured (2 nodes) with dedicated 10Gb Data network and 10Gb Cluster/Storage network.
I did have to change IP's on one node, which removed an old IP 172.16.10.11 (data) from node1 leaving it with only one IP on the correct interface 172.16.10.12 (data) and one IP 172.16.101.11 (Cluster/Storage ), since I had configured the node with the data network initially on the wrong interface (regular internal 1Gb NIC instead of the proper 10Gb nic), I changed the "Cluster --> Options --> Migration Settings" to the Cluster/Storage Network, ensure /etc/hosts was updated and restarted the cluster with "systemctl restart pve-cluster" and it would migrate using the proper Cluster/Storage Network leaving the data NIC untouched for the guests regular workload, migrating in near real-time now.
Thanks for the walkthrough, this one was a bugger to ID and solve.
I had a cluster configured (2 nodes) with dedicated 10Gb Data network and 10Gb Cluster/Storage network.
I did have to change IP's on one node, which removed an old IP 172.16.10.11 (data) from node1 leaving it with only one IP on the correct interface 172.16.10.12 (data) and one IP 172.16.101.11 (Cluster/Storage ), since I had configured the node with the data network initially on the wrong interface (regular internal 1Gb NIC instead of the proper 10Gb nic), I changed the "Cluster --> Options --> Migration Settings" to the Cluster/Storage Network, ensure /etc/hosts was updated and restarted the cluster with "systemctl restart pve-cluster" and it would migrate using the proper Cluster/Storage Network leaving the data NIC untouched for the guests regular workload, migrating in near real-time now.
Thanks for the walkthrough, this one was a bugger to ID and solve.