I don't understand what's going wrong..
Running Ubuntu Server for plex as main use, a VM, have a couple of drives passed through to the VM.
All drives are Luks encrypted, works fine with unlocking/mounting with crypttab.
Streaming works fine, but When i try to copy or move files between the drives the speed starts really fine 250+MB/s (at least between the Enterprise drives).
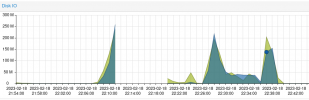
But it starts throttling after say 10-15GB until it drops down slowly alteast when lookin at the graphs (summary).
Inside the VM the transfer freezes, I can't poll any more data from the "writing" disk, and when this happens it's also impossible to shutdown the VM since the ubuntu shutdown stops at failure to unmont filesystem and fails to kill process id that transfer files.
I do see the VMs ram topping out, but after a hard reboot of the whole server I can see that about 10-15 gb are written to the destination drive.
I really start to enjoy using PVE and o it for two more servers as well, but this is so frustrating my plex server cant have these issues, do I need to move back to Ubuntu baremetall?
My VM
The attached file shows how the speed drops on IO for disks, till its stuck and i have to shutdown the whole system.
Running Ubuntu Server for plex as main use, a VM, have a couple of drives passed through to the VM.
All drives are Luks encrypted, works fine with unlocking/mounting with crypttab.
Streaming works fine, but When i try to copy or move files between the drives the speed starts really fine 250+MB/s (at least between the Enterprise drives).
But it starts throttling after say 10-15GB until it drops down slowly alteast when lookin at the graphs (summary).
Inside the VM the transfer freezes, I can't poll any more data from the "writing" disk, and when this happens it's also impossible to shutdown the VM since the ubuntu shutdown stops at failure to unmont filesystem and fails to kill process id that transfer files.
I do see the VMs ram topping out, but after a hard reboot of the whole server I can see that about 10-15 gb are written to the destination drive.
I really start to enjoy using PVE and o it for two more servers as well, but this is so frustrating my plex server cant have these issues, do I need to move back to Ubuntu baremetall?
My VM
Code:
gent: 1
boot: order=scsi0;ide2;net0
cores: 11
cpu: host
ide2: none,media=cdrom
memory: 25000
meta: creation-qemu=7.1.0,ctime=1676379437
name: Ubuntu-Plex2
net0: virtio=*:*:*:*:*,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
sata0: /dev/disk/by-id/ata-Samsung_SSD_850_E*,backup=0,size=488386584K,ssd=1
sata1: /dev/disk/by-id/ata-KINGSTON_SUV500*,backup=0,size=468851544K,ssd=1
scsi0: local-lvm:vm-102-disk-0,iothread=1,size=180G
scsi10: /dev/disk/by-id/ata-TOSHIBA_HDWQ140*backup=0,size=3907018584K
scsi11: /dev/disk/by-id/ata-WDC_WD30*,backup=0,size=2930266584K
scsi12: /dev/disk/by-id/ata-WDC_WD30*,backup=0,size=2930266584K
scsi13: /dev/disk/by-id/ata-WDC_WD30*,backup=0,size=2930266584K
scsi14: /dev/disk/by-id/ata-WDC_WD30*,backup=0,size=2930266584K
scsi2: /dev/disk/by-id/nvme-Force_MP510*,backup=0,size=937692504K,ssd=1
scsi5: /dev/disk/by-id/ata-TOSHIBA_MG07ACA14TE*,backup=0,size=13351934M
scsi6: /dev/disk/by-id/ata-TOSHIBA_MG07ACA14TE*,backup=0,size=13351934M
scsi7: /dev/disk/by-id/ata-TOSHIBA_MG07ACA14TE*,backup=0,size=13039G
scsi8: /dev/disk/by-id/ata-TOSHIBA_MG07ACA14TE*,backup=0,size=13351934M
scsi9: /dev/disk/by-id/ata-TOSHIBA_MG07ACA14TE*,backup=0,size=13039G
scsihw: virtio-scsi-single
smbios1: uuid=0*
sockets: 1
usb0: host=1058:0748
usb1: host=0bc2:ab2e
vmgenid: *The attached file shows how the speed drops on IO for disks, till its stuck and i have to shutdown the whole system.
Attachments
Last edited: