Dear Community,
this is a followup of https://forum.proxmox.com/threads/vm-filesystem-corruption-after-suspending-reboot.168690/
I was suspecting hibernation to be the cause of the data corruption but further investigation now show that the backup process was actually causing it.
Investigation - Timeline of events:
Attached a log from the backup job.
The first backups resulted in a timeout shortly after they started.
Starting with VM 103 there were severe errors:
Obviously there were communication issues with the PBS system. More on that below.
In any case, the backup process failed at a given point in time and left the VM in an inconsistent state.
During my investigation for the root cause, I successfully and unintentionally reproduced the data corruption multiple times.
IMHO the system should be resilient to this type of errors and ensure that the VMs are kept in good working order.
It looks like there were many yet unsuccessful retries. It looks like the system tried hard to avoid this problem.
I saw that the backup failed but was absolutely not aware at this time that my VMs were corrupted.
Root cause:
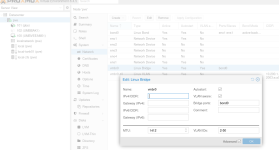
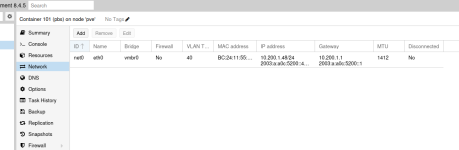
In short: The MTU of the network interface of PBS was set to 1412 bytes.
Yes, this setting is incorrect and it's my fault ;-)
This was configured to ensure that no packets greater than MTU are sent to an offsite mirror.
Before the update, I did not notice and issue with backup nor did the logs show problems.
I think that the server reboot did something different to the PBS container than just setting the MTU (& rebooting the LXC).
How to reproduce the issue:
Since I unintentionally corrupted my systems several times today by "just" running a backup, the issue is easy to reproduce by just setting the PBS containers MTU to a lower value like 1412 (in my case).
In reality this can happen on WAN/VPN links when fragmentation is disabled (df-bit sent or not ignored by firewall) or when MSS clamping setting is incorrect.
Expected behaviour:
When there is a problem talking to PBS for whatever reason, the system must ensure that the source VMs are reverted to their original state.
Please let me know if more information is required.
I'd like to share more details about the failed commands if another log contains such information.
Best regards,
Bernhard
this is a followup of https://forum.proxmox.com/threads/vm-filesystem-corruption-after-suspending-reboot.168690/
I was suspecting hibernation to be the cause of the data corruption but further investigation now show that the backup process was actually causing it.
Investigation - Timeline of events:
- PVE Server #1 was updated from 8.4.1 to 8.4.5, then rebooted
- PVE Server #2 (with PBS as container used to backup server #1) was updated & rebooted as well
- PVE Server #1 & #2 came back online with no obvious problems
- Backup job scheduled for 9pm was started automatically
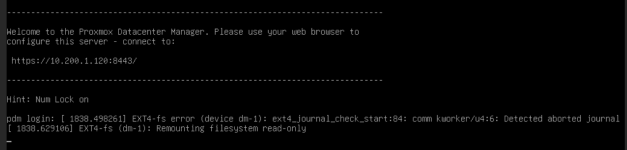
- This morning many linux VMs had a corrupted filesystem, were freezed or unable to boot
Attached a log from the backup job.
The first backups resulted in a timeout shortly after they started.
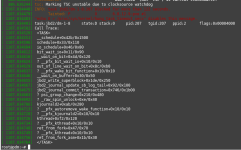
Starting with VM 103 there were severe errors:
Code:
103: 2025-07-20 21:52:59 ERROR: VM 103 qmp command 'guest-fsfreeze-thaw' failed - got timeout
103: 2025-07-20 21:52:59 INFO: started backup task '341012e3-8635-4c9a-aa56-d73eb8a82913'
103: 2025-07-20 21:52:59 INFO: resuming VM again
103: 2025-07-20 21:53:44 ERROR: VM 103 qmp command 'cont' failed - unable to connect to VM 103 qmp socket - timeout after 449 retries
103: 2025-07-20 21:53:44 INFO: aborting backup job
103: 2025-07-20 22:03:44 ERROR: VM 103 qmp command 'backup-cancel' failed - unable to connect to VM 103 qmp socket - timeout after 5973 retries
103: 2025-07-20 22:03:44 INFO: resuming VM again
103: 2025-07-20 22:04:29 ERROR: Backup of VM 103 failed - VM 103 qmp command 'cont' failed - unable to connect to VM 103 qmp socket - timeout after 449 retriesObviously there were communication issues with the PBS system. More on that below.
In any case, the backup process failed at a given point in time and left the VM in an inconsistent state.
During my investigation for the root cause, I successfully and unintentionally reproduced the data corruption multiple times.
IMHO the system should be resilient to this type of errors and ensure that the VMs are kept in good working order.
It looks like there were many yet unsuccessful retries. It looks like the system tried hard to avoid this problem.
I saw that the backup failed but was absolutely not aware at this time that my VMs were corrupted.
Root cause:
In short: The MTU of the network interface of PBS was set to 1412 bytes.
Yes, this setting is incorrect and it's my fault ;-)
This was configured to ensure that no packets greater than MTU are sent to an offsite mirror.
Before the update, I did not notice and issue with backup nor did the logs show problems.
I think that the server reboot did something different to the PBS container than just setting the MTU (& rebooting the LXC).
How to reproduce the issue:
Since I unintentionally corrupted my systems several times today by "just" running a backup, the issue is easy to reproduce by just setting the PBS containers MTU to a lower value like 1412 (in my case).
In reality this can happen on WAN/VPN links when fragmentation is disabled (df-bit sent or not ignored by firewall) or when MSS clamping setting is incorrect.
Expected behaviour:
When there is a problem talking to PBS for whatever reason, the system must ensure that the source VMs are reverted to their original state.
Please let me know if more information is required.
I'd like to share more details about the failed commands if another log contains such information.
Best regards,
Bernhard
Attachments
Last edited:

")
")