Hello everyone,
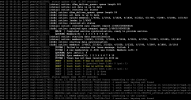
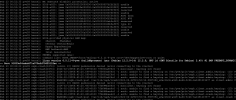
there are some other reports in the forum, but I don't know if they are directly related. We have started to upgrade our 10 Node cluster to PVE 8.1. Currently there are 2 nodes on 8.1, a SuperMicro and a DELL PowerEdge R740xd. The DELL system crahshed once a day, we then receive the FENCING message by e-mail. There is no reason for this in the logs! Shortly before the server reboots, there are no signs in the log. The time is also always different (10:47 / 10:56 / 04:26).
PVE 7 Nodes: Version 7.4.16
PVE 8 Nodes: Version 8.1.4
CEPH 17.2.5 / 17.2.6
Kernel Version on PVE8 Nodes: Linux 6.5.11-8-pve (2024-01-30T12:27Z)
Before the upgrade to Version 8, there were no problems in this direction.
Does anyone have similar problems and/or an idea how to troubleshoot?
Best regards
Tan
there are some other reports in the forum, but I don't know if they are directly related. We have started to upgrade our 10 Node cluster to PVE 8.1. Currently there are 2 nodes on 8.1, a SuperMicro and a DELL PowerEdge R740xd. The DELL system crahshed once a day, we then receive the FENCING message by e-mail. There is no reason for this in the logs! Shortly before the server reboots, there are no signs in the log. The time is also always different (10:47 / 10:56 / 04:26).
PVE 7 Nodes: Version 7.4.16
PVE 8 Nodes: Version 8.1.4
CEPH 17.2.5 / 17.2.6
Kernel Version on PVE8 Nodes: Linux 6.5.11-8-pve (2024-01-30T12:27Z)
Before the upgrade to Version 8, there were no problems in this direction.
Does anyone have similar problems and/or an idea how to troubleshoot?
Best regards
Tan




")


")