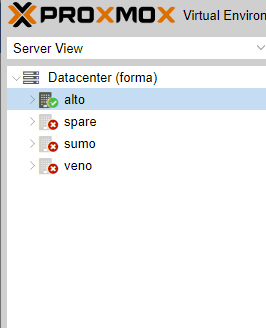
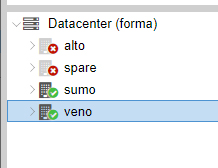
Hello,
after restart of one node (4) in my cluster which has 4 nodes, synchronisation stop working on this node.
corosync.conf is same on all nodes:
output from corosync nodes:
Node 1 was restarted and output from
systemctl status pve-cluster.service
Node 2 is stopped.
Could you help me painlessly rebuild cluster?
Thanks
after restart of one node (4) in my cluster which has 4 nodes, synchronisation stop working on this node.
corosync.conf is same on all nodes:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: veno
nodeid: 4
quorum_votes: 1
ring0_addr: veno
}
node {
name: alto
nodeid: 1
quorum_votes: 1
ring0_addr: alto
}
node {
name: spare
nodeid: 2
quorum_votes: 1
ring0_addr: spare
}
node {
name: sumo
nodeid: 3
quorum_votes: 1
ring0_addr: sumo
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: forma
config_version: 8
ip_version: ipv4
secauth: on
version: 2
interface {
bindnetaddr: X.X.X.X
ringnumber: 0
}
}
debug: off
to_syslog: yes
}
nodelist {
node {
name: veno
nodeid: 4
quorum_votes: 1
ring0_addr: veno
}
node {
name: alto
nodeid: 1
quorum_votes: 1
ring0_addr: alto
}
node {
name: spare
nodeid: 2
quorum_votes: 1
ring0_addr: spare
}
node {
name: sumo
nodeid: 3
quorum_votes: 1
ring0_addr: sumo
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: forma
config_version: 8
ip_version: ipv4
secauth: on
version: 2
interface {
bindnetaddr: X.X.X.X
ringnumber: 0
}
}
output from corosync nodes:
notice [MAIN ] Corosync Cluster Engine ('2.4.4-dirty'): started and ready to provide service.
info [MAIN ] Corosync built-in features: dbus rdma monitoring watchdog systemd xmlconf qdevices qnetd snmp pie relro bindnow
warning [MAIN ] interface section bindnetaddr is used together with nodelist. Nodelist one is going to be used.
warning [MAIN ] Please migrate config file to nodelist.
info [MAIN ] Corosync built-in features: dbus rdma monitoring watchdog systemd xmlconf qdevices qnetd snmp pie relro bindnow
warning [MAIN ] interface section bindnetaddr is used together with nodelist. Nodelist one is going to be used.
warning [MAIN ] Please migrate config file to nodelist.
Node 1 was restarted and output from
systemctl status pve-cluster.service
● pve-cluster.service - The Proxmox VE cluster filesystem
Loaded: loaded (/lib/systemd/system/pve-cluster.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2019-06-17 20:11:52 CEST; 14min ago
Process: 17423 ExecStartPost=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS)
Process: 17407 ExecStart=/usr/bin/pmxcfs (code=exited, status=0/SUCCESS)
Main PID: 17409 (pmxcfs)
Tasks: 5 (limit: 4915)
Memory: 31.5M
CPU: 924ms
CGroup: /system.slice/pve-cluster.service
└─17409 /usr/bin/pmxcfs
Jun 17 20:11:51 alto pmxcfs[17409]: [dcdb] crit: cpg_initialize failed: 2
Jun 17 20:11:51 alto pmxcfs[17409]: [dcdb] crit: can't initialize service
Jun 17 20:11:51 alto pmxcfs[17409]: [status] crit: cpg_initialize failed: 2
Jun 17 20:11:51 alto pmxcfs[17409]: [status] crit: can't initialize service
Jun 17 20:11:52 alto systemd[1]: Started The Proxmox VE cluster filesystem.
Jun 17 20:11:57 alto pmxcfs[17409]: [status] notice: update cluster info (cluster name forma, version = 8)
Jun 17 20:11:58 alto pmxcfs[17409]: [dcdb] notice: members: 1/17409
Jun 17 20:11:58 alto pmxcfs[17409]: [dcdb] notice: all data is up to date
Jun 17 20:11:58 alto pmxcfs[17409]: [status] notice: members: 1/17409
Jun 17 20:11:58 alto pmxcfs[17409]: [status] notice: all data is up to date
Loaded: loaded (/lib/systemd/system/pve-cluster.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2019-06-17 20:11:52 CEST; 14min ago
Process: 17423 ExecStartPost=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS)
Process: 17407 ExecStart=/usr/bin/pmxcfs (code=exited, status=0/SUCCESS)
Main PID: 17409 (pmxcfs)
Tasks: 5 (limit: 4915)
Memory: 31.5M
CPU: 924ms
CGroup: /system.slice/pve-cluster.service
└─17409 /usr/bin/pmxcfs
Jun 17 20:11:51 alto pmxcfs[17409]: [dcdb] crit: cpg_initialize failed: 2
Jun 17 20:11:51 alto pmxcfs[17409]: [dcdb] crit: can't initialize service
Jun 17 20:11:51 alto pmxcfs[17409]: [status] crit: cpg_initialize failed: 2
Jun 17 20:11:51 alto pmxcfs[17409]: [status] crit: can't initialize service
Jun 17 20:11:52 alto systemd[1]: Started The Proxmox VE cluster filesystem.
Jun 17 20:11:57 alto pmxcfs[17409]: [status] notice: update cluster info (cluster name forma, version = 8)
Jun 17 20:11:58 alto pmxcfs[17409]: [dcdb] notice: members: 1/17409
Jun 17 20:11:58 alto pmxcfs[17409]: [dcdb] notice: all data is up to date
Jun 17 20:11:58 alto pmxcfs[17409]: [status] notice: members: 1/17409
Jun 17 20:11:58 alto pmxcfs[17409]: [status] notice: all data is up to date
● pve-cluster.service - The Proxmox VE cluster filesystem
Loaded: loaded (/lib/systemd/system/pve-cluster.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2019-06-17 20:24:30 CEST; 2min 7s ago
Process: 25546 ExecStartPost=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS)
Process: 25444 ExecStart=/usr/bin/pmxcfs (code=exited, status=0/SUCCESS)
Main PID: 25452 (pmxcfs)
Tasks: 5 (limit: 4915)
Memory: 34.8M
CPU: 572ms
CGroup: /system.slice/pve-cluster.service
└─25452 /usr/bin/pmxcfs
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: received sync request (epoch 3/25452/00000001)
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: received all states
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: leader is 3/25452
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: synced members: 3/25452, 4/2413
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: start sending inode updates
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: sent all (0) updates
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: all data is up to date
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: received all states
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: all data is up to date
Jun 17 20:24:30 sumo systemd[1]: Started The Proxmox VE cluster filesystem.
Loaded: loaded (/lib/systemd/system/pve-cluster.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2019-06-17 20:24:30 CEST; 2min 7s ago
Process: 25546 ExecStartPost=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS)
Process: 25444 ExecStart=/usr/bin/pmxcfs (code=exited, status=0/SUCCESS)
Main PID: 25452 (pmxcfs)
Tasks: 5 (limit: 4915)
Memory: 34.8M
CPU: 572ms
CGroup: /system.slice/pve-cluster.service
└─25452 /usr/bin/pmxcfs
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: received sync request (epoch 3/25452/00000001)
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: received all states
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: leader is 3/25452
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: synced members: 3/25452, 4/2413
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: start sending inode updates
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: sent all (0) updates
Jun 17 20:24:29 sumo pmxcfs[25452]: [dcdb] notice: all data is up to date
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: received all states
Jun 17 20:24:29 sumo pmxcfs[25452]: [status] notice: all data is up to date
Jun 17 20:24:30 sumo systemd[1]: Started The Proxmox VE cluster filesystem.
Node 2 is stopped.
Could you help me painlessly rebuild cluster?
Thanks