Hallo, anbei die Log, Fehler kam die Nacht, bis in der Nacht war nichts grau.
Dez 16 13:32:14 pegasus corosync[975]: [QUORUM] Sync members[1]: 1
Dez 16 13:32:14 pegasus corosync[975]: [QUORUM] Sync joined[1]: 1
Dez 16 13:32:14 pegasus corosync[975]: [TOTEM ] A new membership (1.7d) was formed. Members joined: 1
Dez 16 13:32:14 pegasus corosync[975]: [QUORUM] Members[1]: 1
Dez 16 13:32:14 pegasus corosync[975]: [MAIN ] Completed service synchronization, ready to provide service.
Dez 16 13:32:14 pegasus systemd[1]: Started corosync.service - Corosync Cluster Engine.
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] link: Resetting MTU for link 0 because host 3 joined
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] host: host: 3 (passive) best link: 0 (pri: 1)
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] link: Resetting MTU for link 0 because host 2 joined
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] host: host: 2 (passive) best link: 0 (pri: 1)
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] pmtud: PMTUD link change for host: 3 link: 0 from 469 to 1397
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] pmtud: PMTUD link change for host: 2 link: 0 from 469 to 1397
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] pmtud: Global data MTU changed to: 1397
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] link: Resetting MTU for link 0 because host 4 joined
Dez 16 13:32:16 pegasus corosync[975]: [KNET ] host: host: 4 (passive) best link: 0 (pri: 1)
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] rx: host: 5 link: 0 is up
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] link: Resetting MTU for link 0 because host 5 joined
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] host: host: 5 (passive) best link: 0 (pri: 1)
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] pmtud: PMTUD link change for host: 4 link: 0 from 469 to 1397
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] pmtud: PMTUD link change for host: 5 link: 0 from 469 to 1397
Dez 16 13:32:17 pegasus corosync[975]: [KNET ] pmtud: Global data MTU changed to: 1397
Dez 16 13:32:17 pegasus corosync[975]: [QUORUM] Sync members[5]: 1 2 3 4 5
Dez 16 13:32:17 pegasus corosync[975]: [QUORUM] Sync joined[4]: 2 3 4 5
Dez 16 13:32:17 pegasus corosync[975]: [TOTEM ] A new membership (1.81) was formed. Members joined: 2 3 4 5
Dez 16 13:32:17 pegasus corosync[975]: [QUORUM] This node is within the primary component and will provide service.
Dez 16 13:32:17 pegasus corosync[975]: [QUORUM] Members[5]: 1 2 3 4 5
Dez 16 13:32:17 pegasus corosync[975]: [MAIN ] Completed service synchronization, ready to provide service.
Dez 16 15:39:13 pegasus corosync[975]: [TOTEM ] Retransmit List: b7a8
root@pegasus:~# journalctl -u corosync --since="1 days ago"
-- No entries --
root@pegasus:~# date
Do 18. Dez 11:33:05 CET 2025
root@pegasus:~#
service pvedaemon status
● pvedaemon.service - PVE API Daemon
Loaded: loaded (/usr/lib/systemd/system/pvedaemon.service; enabled; preset: enabled)
Active: active (running) since Tue 2025-12-16 13:32:19 CET; 1 day 22h ago
Invocation: 2be9b5ac79ff4e4cae9b7b6aac1588e0
Process: 1034 ExecStart=/usr/bin/pvedaemon start (code=exited, status=0/SUCCESS)
Main PID: 1102 (pvedaemon)
Tasks: 4 (limit: 9301)
Memory: 175.9M (peak: 194.9M)
CPU: 1min 42.017s
CGroup: /system.slice/pvedaemon.service
├─ 1102 pvedaemon
├─290645 "pvedaemon worker"
├─414817 "pvedaemon worker"
└─417578 "pvedaemon worker"
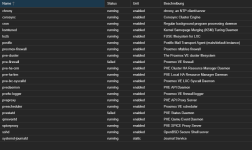
Nachdem der Fehler aufgetreten ist, sieht die Serviceliste so aus... Siehe Screenshot im Anhang.
Log pvestat sagt gestern Abend:
Dec 16 18:32:53 pegasus pvestatd[1075]: status update time (6.080 seconds)
Dec 17 23:48:19 pegasus systemd[1]: pvestatd.service: Main process exited, code=killed, status=11/SEGV
Dec 17 23:48:19 pegasus systemd[1]: pvestatd.service: Failed with result 'signal'.
Dec 17 23:48:19 pegasus systemd[1]: pvestatd.service: Consumed 1h 3min 6.169s CPU time, 186.2M memory peak.
Firewall syslog:
Dec 18 00:16:59 pegasus systemd[1]: pve-firewall.service: Main process exited, code=killed, status=11/SEGV
Dec 18 00:16:59 pegasus systemd[1]: pve-firewall.service: Failed with result 'signal'.
Dec 18 00:16:59 pegasus systemd[1]: pve-firewall.service: Consumed 41min 58.624s CPU time, 123.5M memory peak.