Hi team, community,
Need some help/guidance/know-how on how to proceed with troubleshooting and resolving the ceph performance issues we are currently observing.
The setup
The cluster is stretched primarily across 2 datacenters.
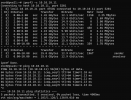
The network between the DCs is 10GB/s, the latency is 1.1ms RTT - see attached results from ping and iperf.
3 servers in each DC, 4 OSD's per server, 24 OSDs in total.
The OSD's are 2TB Samsung 970 EVO Plus NVMe - I know consumer grade...
We also have one server in 3rd DC that is member of the cluster and has ceph monitor - to ensure quorum in case one of the DCs fail.
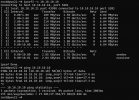
The third DC is farther away, the link is about 2GB/s with 17.5 ms RTT latency - see second screenshot.
There are no workloads here, only corosync and ceph mon.
Not sure if this monitor can cause issues somehow....
The config
Ceph is configured with min of 2 and max of 4 replicas. This is to ensure that at least 2 replicas are available in one of the datacenters.
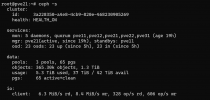
The crush map is attached. The ceph status is normal, please note the current load:
The problem
Most of our workloads work with many small files, we have being working on migrating VMs to the cluster which is now paused until we resolve this.
Initially the performance was OK, but after migrating 20-ish production servers the performance issues have became visible.
The simple test we did is moving the VM disk to the local-zfs volume (zfs mirror on 2x Micron MTFDDAF480TDS for PVE OS), after which the performance issues disappeared for that workload.
Moving back to ceph re-creates the problem asap.
The troubleshooting
We have run few test to try and troubleshoot the issue - our primary focus was around the network and the NVMe performance.
We have being doing multiple iperf test of the network - peak/quiet hours, and have monitored the network load via iftop. No obvious trouble in this space.
Next we went after the disk and started with rados bench which have not yield any obvious problems problems - see next attachment with the results.
writes
reads
Next we decided to test the disks with fio...
Samsung 970 EVO Plus 2TB NVMe
Micron MTFDDAF480TDS 500GB SSD
This the fio command we ran
Obviously the Micron's have much better performance although being SSD's. Consumer vs. Enterprise is not a mith.
The conclusion
Looks like the whole team here is joining brains around running out of IOPS on the Samsung NVMEs... Note the output of the "ceph -s" command.
The remediation for this would be to swap with enterprise NVMEs or even SSDs since these have lot more IOPS and better performance.
The ASK
Are we going in the right direction here?
Is there any other test that we can perform to validate the issues?
We would like to repeat the test after remediation.
Please let me know if additional details are needed.
MANY THANKS!
Need some help/guidance/know-how on how to proceed with troubleshooting and resolving the ceph performance issues we are currently observing.
The setup
The cluster is stretched primarily across 2 datacenters.
The network between the DCs is 10GB/s, the latency is 1.1ms RTT - see attached results from ping and iperf.
3 servers in each DC, 4 OSD's per server, 24 OSDs in total.
The OSD's are 2TB Samsung 970 EVO Plus NVMe - I know consumer grade...
We also have one server in 3rd DC that is member of the cluster and has ceph monitor - to ensure quorum in case one of the DCs fail.
The third DC is farther away, the link is about 2GB/s with 17.5 ms RTT latency - see second screenshot.
There are no workloads here, only corosync and ceph mon.
Not sure if this monitor can cause issues somehow....
The config
Ceph is configured with min of 2 and max of 4 replicas. This is to ensure that at least 2 replicas are available in one of the datacenters.
The crush map is attached. The ceph status is normal, please note the current load:
Code:
io:
client: 6.3 MiB/s rd, 8.4 MiB/s wr, 328 op/s rd, 606 op/s wrThe problem
Most of our workloads work with many small files, we have being working on migrating VMs to the cluster which is now paused until we resolve this.
Initially the performance was OK, but after migrating 20-ish production servers the performance issues have became visible.
The simple test we did is moving the VM disk to the local-zfs volume (zfs mirror on 2x Micron MTFDDAF480TDS for PVE OS), after which the performance issues disappeared for that workload.
Moving back to ceph re-creates the problem asap.
The troubleshooting
We have run few test to try and troubleshoot the issue - our primary focus was around the network and the NVMe performance.
We have being doing multiple iperf test of the network - peak/quiet hours, and have monitored the network load via iftop. No obvious trouble in this space.
Next we went after the disk and started with rados bench which have not yield any obvious problems problems - see next attachment with the results.
writes
Code:
Total time run: 100.061
Total writes made: 15148
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 605.549
Stddev Bandwidth: 85.0185
Max bandwidth (MB/sec): 1196
Min bandwidth (MB/sec): 480
Average IOPS: 151
Stddev IOPS: 21.2546
Max IOPS: 299
Min IOPS: 120
Average Latency(s): 0.105664
Stddev Latency(s): 0.0538286
Max latency(s): 0.375314
Min latency(s): 0.0167309reads
Code:
Total time run: 100.061
Total writes made: 15148
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 605.549
Stddev Bandwidth: 85.0185
Max bandwidth (MB/sec): 1196
Min bandwidth (MB/sec): 480
Average IOPS: 151
Stddev IOPS: 21.2546
Max IOPS: 299
Min IOPS: 120
Average Latency(s): 0.105664
Stddev Latency(s): 0.0538286
Max latency(s): 0.375314
Min latency(s): 0.0167309Next we decided to test the disks with fio...
Samsung 970 EVO Plus 2TB NVMe
Code:
Jobs: 1 (f=1): [W(1)][100.0%][w=2230KiB/s][w=557 IOPS][eta 00m:00s]Micron MTFDDAF480TDS 500GB SSD
Code:
Jobs: 1 (f=1): [W(1)][100.0%][w=68.0MiB/s][w=17.7k IOPS][eta 00m:00s]This the fio command we ran
Code:
fio --ioengine=libaio --filename=/dev/sdb --direct=1 --sync=1 --rw=write --bs=4K --numjobs=1 --iodepth=1 --runtime=60 --time_based --name=fioObviously the Micron's have much better performance although being SSD's. Consumer vs. Enterprise is not a mith.
The conclusion
Looks like the whole team here is joining brains around running out of IOPS on the Samsung NVMEs... Note the output of the "ceph -s" command.
The remediation for this would be to swap with enterprise NVMEs or even SSDs since these have lot more IOPS and better performance.
The ASK
Are we going in the right direction here?
Is there any other test that we can perform to validate the issues?
We would like to repeat the test after remediation.
Please let me know if additional details are needed.
MANY THANKS!
Attachments
Last edited:


")