Hallo liebes Forum,
ich habe Probleme mit meinem CEPH. Ganz genau lokaliesieren kann ich das Problem leider nicht. Am Anfang habe ich es auch gerne Verdrängt, bzw. ist mir im Testing nicht aufgefallen.
Ganz verschweigen will ich nicht, dass ich nicht die Ideale Anforderung an CEPH fahre bzw. Umgesetzt habe. Gründe später.
Seit dem im Ceph aber ein PostgreSQL-Server läuft werden die Ausmaße leider sichtbar und sorgt für sehr viel Unmut im Unternehmen.
Es gibt eine handvoll Themen zu CEPH und Latenzproblemen hier, oftmals leider auch der Hinweis zu - Mehr Hardware bessere Hardware. Ich denke unsere Hardware ist gut.
Erstmal ein paar Fakten:
CPU und RAM:
2x HPe G10 380 mit 1024GB RAM 24 Kerne Gold 6146 CPU @ 3.20GHz
1x HPe G10 380 mit 512GB RAM 32 Kerne Gold 6142M CPU @ 2.60GHz (Die CPUs werden noch zu den oberen CPUs ersetzt)
HDDs:
LEIDER nur Platz für 6x Speicher in 2,5" , dabei aber ein Volumen von 29GB + Reserve + Ausfallsicherheit
Daher ist die Entscheidung (Budget gezwungen) auf Samsung QVO 8TB gegangen - im Raid 5. 5x8TB + 1x Ausfallsicherheit
Ja Raidcontroller sollen mit Ceph eigentlich nicht genutzt werden ::
Warum ist es doch passiert? Es soll die Einschränkungen die SATA mit sich bringen minimieren durch verteiltes Lesen / Schreiben.
die letzten 2 Slots werden das Betriebssystem im Raid 1 genutzt.
Ich bin nicht nur 'kein Fan' von der SD-Kartengeschichte bei HP, sondern auch absoluter SD-Kartenhasser bei HP Umsetzungen. Seit HP nach dem G7 Modell die Idee hatte die Slots auf dem Board zu packen - teilweise unter den Risers, statt wie vorher Komfortable in der oberen Querstrebe zu montieren.
Netzwerk:
jeder Server ist mit 4x10GBe angebunden, es werden jedoch BONDS genutzt.
Ich versuche es mal etwas aufzumalen:
Bond10: 2x10GBe LACP -> Switch 1
Bond20: 2x10GBe LACP -> Switch 2
Bond 0: Active (Bond 10) Passic (Bond 20)
vmbr0 -> Bond0
vmbr102->vlan102->Bond0
SDN-Configs -> vmbr0
die vmbr102-vlan102 Konstellation ist leider dadurch entstanden, dass unser Testsytem noch ein Proxmox 7 war, und das Feature mit SDN erst später dazu kam.
die vmbr102 wird von Proxmox und Ceph genutzt (bzw. der IPKreis)
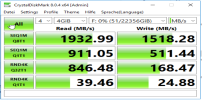
HDD Benchmarks
Wie soll ich weiter machen?
Ich habe direkt nach dem erstellen:
Nicht aussagekräftig, aber ein Anhaltspunkt - Raid 5 Test unter nativ Windows Server


identischer Test jetzt: Windows Server VM unter Proxmox -> Ceph

-----------------------------------------------------------------
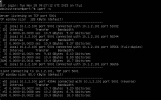
RADOS-Benchmarks:
Benchmark Netzwerk
Container1 / HV02 ---> HV03 / Container2
Server listening on TCP port 5001
TCP window size: 128 KByte (default)
------------------------------------------------------------
[ 1] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 59698
[ ID] Interval Transfer Bandwidth
[ 1] 0.0000-10.0028 sec 10.8 GBytes 9.31 Gbits/sec
[ 2] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 52196 (full-duplex)
[ ID] Interval Transfer Bandwidth
[ *2] 0.0000-10.0001 sec 10.6 GBytes 9.12 Gbits/sec
[ 2] 0.0000-10.0043 sec 7.04 GBytes 6.05 Gbits/sec
[SUM] 0.0000-10.0035 sec 17.7 GBytes 15.2 Gbits/sec
[ 3] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 60084
[ ID] Interval Transfer Bandwidth
[ 3] 0.0000-10.0029 sec 10.8 GBytes 9.28 Gbits/sec
[ 4] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 54818
[ ID] Interval Transfer Bandwidth
[ 4] 0.0000-10.0033 sec 10.8 GBytes 9.27 Gbits/sec
[ 5] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 53274
[ ID] Interval Transfer Bandwidth
[ 5] 0.0000-10.0034 sec 10.8 GBytes 9.29 Gbits/sec
[ 6] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 37330
[ ID] Interval Transfer Bandwidth
[ 6] 0.0000-10.0030 sec 10.9 GBytes 9.32 Gbits/sec
---------------------------------------- Netzwerkspeed aus Virtuellen Server ----------------------------------------
Die Frage aller Fragen:
- mir fehlen Vergleichswerte: Kann jemand die Werte beurteilen (objektiv bitte ;-) ) - ob die für die Leistung zu erwarten ist, oder ob die einfach nur Mies ist!
- sieht jemand auf den ersten Blick aus seiner Erfahrung heraus, wo definitiv schon mal eine Stellschraube angepasst werden kann?
- besteht die Möglichkeit ein SSD-WriteCache (wie ZFS) zu nutzen um die Latenz / Write-Throuput zu minimieren bzw. zu verbessern?
=> Ich kann gerne, falls es interessiert und hilfreich ist, noch ein paar Worte in einem neuen "Post" zum Thema PostgreSQL schreiben.
Proxmox kenne ich sonst nur aus "Stand-Alone" Umgebungen, aber wir wollten im Unternehmen lieber etwas inovatier Unterwegs sein, als was MS und VMWare angeht. Darum die Entscheidung.
Gruß
Chris
ich habe Probleme mit meinem CEPH. Ganz genau lokaliesieren kann ich das Problem leider nicht. Am Anfang habe ich es auch gerne Verdrängt, bzw. ist mir im Testing nicht aufgefallen.
Ganz verschweigen will ich nicht, dass ich nicht die Ideale Anforderung an CEPH fahre bzw. Umgesetzt habe. Gründe später.
Seit dem im Ceph aber ein PostgreSQL-Server läuft werden die Ausmaße leider sichtbar und sorgt für sehr viel Unmut im Unternehmen.
Es gibt eine handvoll Themen zu CEPH und Latenzproblemen hier, oftmals leider auch der Hinweis zu - Mehr Hardware bessere Hardware. Ich denke unsere Hardware ist gut.
Erstmal ein paar Fakten:
CPU und RAM:
2x HPe G10 380 mit 1024GB RAM 24 Kerne Gold 6146 CPU @ 3.20GHz
1x HPe G10 380 mit 512GB RAM 32 Kerne Gold 6142M CPU @ 2.60GHz (Die CPUs werden noch zu den oberen CPUs ersetzt)
HDDs:
LEIDER nur Platz für 6x Speicher in 2,5" , dabei aber ein Volumen von 29GB + Reserve + Ausfallsicherheit
Daher ist die Entscheidung (Budget gezwungen) auf Samsung QVO 8TB gegangen - im Raid 5. 5x8TB + 1x Ausfallsicherheit
Ja Raidcontroller sollen mit Ceph eigentlich nicht genutzt werden ::
Warum ist es doch passiert? Es soll die Einschränkungen die SATA mit sich bringen minimieren durch verteiltes Lesen / Schreiben.
die letzten 2 Slots werden das Betriebssystem im Raid 1 genutzt.
Ich bin nicht nur 'kein Fan' von der SD-Kartengeschichte bei HP, sondern auch absoluter SD-Kartenhasser bei HP Umsetzungen. Seit HP nach dem G7 Modell die Idee hatte die Slots auf dem Board zu packen - teilweise unter den Risers, statt wie vorher Komfortable in der oberen Querstrebe zu montieren.
Netzwerk:
jeder Server ist mit 4x10GBe angebunden, es werden jedoch BONDS genutzt.
Ich versuche es mal etwas aufzumalen:
Bond10: 2x10GBe LACP -> Switch 1
Bond20: 2x10GBe LACP -> Switch 2
Bond 0: Active (Bond 10) Passic (Bond 20)
vmbr0 -> Bond0
vmbr102->vlan102->Bond0
SDN-Configs -> vmbr0
die vmbr102-vlan102 Konstellation ist leider dadurch entstanden, dass unser Testsytem noch ein Proxmox 7 war, und das Feature mit SDN erst später dazu kam.
die vmbr102 wird von Proxmox und Ceph genutzt (bzw. der IPKreis)
HDD Benchmarks
Wie soll ich weiter machen?
Ich habe direkt nach dem erstellen:
Nicht aussagekräftig, aber ein Anhaltspunkt - Raid 5 Test unter nativ Windows Server
identischer Test jetzt: Windows Server VM unter Proxmox -> Ceph
-----------------------------------------------------------------
RADOS-Benchmarks:
[FONT=Calibri]BENCHMARK unserer Umgebung
rados bench -p CephPool01 20 write -b 10M -t 16 --run-name hv03 --no-cleanup
hints = 1
Maintaining 16 concurrent writes of 10485760 bytes to objects of size 10485760 for up to 20 seconds or 0 objects
Object prefix: benchmark_data_hv03_147706
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 15 64 49 489.896 490 0.251826 0.266099
2 15 127 112 559.902 630 0.209806 0.259421
3 15 191 176 586.564 640 0.27616 0.253519
4 15 256 241 602.398 650 0.207485 0.252887
5 15 324 309 617.896 680 0.212533 0.251062
6 15 388 373 621.561 640 0.173464 0.249113
7 15 454 439 627.038 660 0.253977 0.24817
8 15 518 503 628.646 640 0.247359 0.248207
9 15 588 573 636.563 700 0.187355 0.247283
10 15 644 629 628.901 560 0.320112 0.247802
11 15 712 697 633.538 680 0.218555 0.248545
12 15 773 758 631.571 610 0.293426 0.249482
13 15 835 820 630.675 620 0.239612 0.249836
14 15 897 882 629.904 620 0.252076 0.250535
15 15 967 952 634.569 700 0.207261 0.249189
16 15 1028 1013 633.027 610 0.187608 0.249963
17 15 1092 1077 633.433 640 0.255258 0.249917
18 15 1158 1143 634.902 660 0.183843 0.249557
19 15 1220 1205 634.112 620 0.302639 0.249549
2023-11-24T15:47:02.710657+0100 min lat: 0.157275 max lat: 0.502047 avg lat: 0.249024
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
20 15 1287 1272 635.902 670 0.216858 0.249024
Total time run: 20.225
Total writes made: 1288
Write size: 10485760
Object size: 10485760
Bandwidth (MB/sec): 636.836
Stddev Bandwidth: 48.057
Max bandwidth (MB/sec): 700
Min bandwidth (MB/sec): 490
Average IOPS: 63
Stddev IOPS: 4.8057
Max IOPS: 70
Min IOPS: 49
Average Latency(s): 0.248776
Stddev Latency(s): 0.0396325
Max latency(s): 0.502047
Min latency(s): 0.111558
root@hv03:~# rados bench -p CephPool01 20 seq -t 16 --run-name hv03
hints = 1
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 15 149 134 1339.64 1340 0.0781954 0.108113
2 15 273 258 1289.73 1240 0.167968 0.116796
3 15 407 392 1306.42 1340 0.105766 0.117492
4 15 541 526 1314.76 1340 0.0967754 0.117945
5 15 687 672 1343.77 1460 0.0698083 0.115759
6 15 822 807 1344.77 1350 0.16361 0.115954
7 15 964 949 1355.49 1420 0.142912 0.115441
8 15 1099 1084 1354.78 1350 0.0873367 0.115537
9 15 1240 1225 1360.89 1410 0.068914 0.115073
Total time run: 9.44074
Total reads made: 1288
Read size: 10485760
Object size: 10485760
Bandwidth (MB/sec): 1364.3
Average IOPS: 136
Stddev IOPS: 6.31357
Max IOPS: 146
Min IOPS: 124
Average Latency(s): 0.114962
Max latency(s): 0.246078
Min latency(s): 0.0386484
rados -p CephPool01 cleanup benchmark_data[/FONT]
Benchmark Netzwerk
Container1 / HV02 ---> HV03 / Container2
Server listening on TCP port 5001
TCP window size: 128 KByte (default)
------------------------------------------------------------
[ 1] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 59698
[ ID] Interval Transfer Bandwidth
[ 1] 0.0000-10.0028 sec 10.8 GBytes 9.31 Gbits/sec
[ 2] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 52196 (full-duplex)
[ ID] Interval Transfer Bandwidth
[ *2] 0.0000-10.0001 sec 10.6 GBytes 9.12 Gbits/sec
[ 2] 0.0000-10.0043 sec 7.04 GBytes 6.05 Gbits/sec
[SUM] 0.0000-10.0035 sec 17.7 GBytes 15.2 Gbits/sec
[ 3] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 60084
[ ID] Interval Transfer Bandwidth
[ 3] 0.0000-10.0029 sec 10.8 GBytes 9.28 Gbits/sec
[ 4] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 54818
[ ID] Interval Transfer Bandwidth
[ 4] 0.0000-10.0033 sec 10.8 GBytes 9.27 Gbits/sec
[ 5] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 53274
[ ID] Interval Transfer Bandwidth
[ 5] 0.0000-10.0034 sec 10.8 GBytes 9.29 Gbits/sec
[ 6] local 10.1.2.120 port 5001 connected with 10.1.2.121 port 37330
[ ID] Interval Transfer Bandwidth
[ 6] 0.0000-10.0030 sec 10.9 GBytes 9.32 Gbits/sec
---------------------------------------- Netzwerkspeed aus Virtuellen Server ----------------------------------------
Die Frage aller Fragen:
- mir fehlen Vergleichswerte: Kann jemand die Werte beurteilen (objektiv bitte ;-) ) - ob die für die Leistung zu erwarten ist, oder ob die einfach nur Mies ist!
- sieht jemand auf den ersten Blick aus seiner Erfahrung heraus, wo definitiv schon mal eine Stellschraube angepasst werden kann?
- besteht die Möglichkeit ein SSD-WriteCache (wie ZFS) zu nutzen um die Latenz / Write-Throuput zu minimieren bzw. zu verbessern?
=> Ich kann gerne, falls es interessiert und hilfreich ist, noch ein paar Worte in einem neuen "Post" zum Thema PostgreSQL schreiben.
Proxmox kenne ich sonst nur aus "Stand-Alone" Umgebungen, aber wir wollten im Unternehmen lieber etwas inovatier Unterwegs sein, als was MS und VMWare angeht. Darum die Entscheidung.
Gruß
Chris
")



