Hello everyone,
I don't have a problem per se, but I wanted to gather some more opinions.
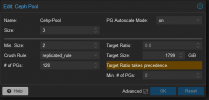
Here's the setup:
- 3 Proxmox nodes in a cluster.
- Hosting provider: Hetzner
- AX41-NVMe (https://www.hetzner.com/de/dedicated-rootserver/ax41-nvme/konfigurator#/)
- Specifications: AMD Ryzen™ 5 3600, 64 GB DDR4 non-ECC.
The nodes are connected to each other via 1GIG for the Proxmox cluster, and additionally, they are dedicatedly connected via 10 GIG LAN for CephStorage.
(I have confirmed through a test with iperf that I am indeed getting 10 Gbps through the connection.)
Each of the three hosts also has a 2 TB NVMe SSD for my Ceph Storage Pool.
I have obtained the following values in a VM, both on ZFS storage and Ceph storage:
ZFS:
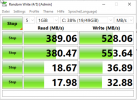
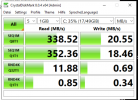
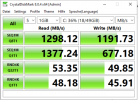
Read:~ 1298 MB/s
Write: ~ 1191 MB/s
Ceph:
Read:~ 338 MB/s
Write: ~ 20 MB/s
Since this is my first experience with Ceph storage, I have the following question:Is this significant performance difference in read and write operations normal, or is there potential for improvement that I am overlooking?
Would adding more nodes improve the performance, or would it be irrelevant?
I am very grateful for any input.
PS: Yes, I am aware that 3 nodes are not enough to operate Ceph with full fault tolerance.
I don't have a problem per se, but I wanted to gather some more opinions.
Here's the setup:
- 3 Proxmox nodes in a cluster.
- Hosting provider: Hetzner
- AX41-NVMe (https://www.hetzner.com/de/dedicated-rootserver/ax41-nvme/konfigurator#/)
- Specifications: AMD Ryzen™ 5 3600, 64 GB DDR4 non-ECC.
The nodes are connected to each other via 1GIG for the Proxmox cluster, and additionally, they are dedicatedly connected via 10 GIG LAN for CephStorage.
(I have confirmed through a test with iperf that I am indeed getting 10 Gbps through the connection.)
Each of the three hosts also has a 2 TB NVMe SSD for my Ceph Storage Pool.
I have obtained the following values in a VM, both on ZFS storage and Ceph storage:
ZFS:
Read:~ 1298 MB/s
Write: ~ 1191 MB/s
Ceph:
Read:~ 338 MB/s
Write: ~ 20 MB/s
Since this is my first experience with Ceph storage, I have the following question:Is this significant performance difference in read and write operations normal, or is there potential for improvement that I am overlooking?
Would adding more nodes improve the performance, or would it be irrelevant?
Code:
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
cluster_network = 192.168.55.0/24
fsid = bcff2142-9dbd-4ed3-9ea9-89b0b4b97ba0
mon_allow_pool_delete = true
mon_host = 192.168.55.14 192.168.55.15 192.168.55.16
ms_bind_ipv4 = true
ms_bind_ipv6 = false
osd_pool_default_min_size = 2
osd_pool_default_size = 3
public_network = 192.168.55.0/24
[client]
keyring = /etc/pve/priv/$cluster.$name.keyring
[mds]
keyring = /var/lib/ceph/mds/ceph-$id/keyring
[mon.Kamino04]
public_addr = 192.168.55.14
[mon.Kamino05]
public_addr = 192.168.55.15
[mon.Kamino06]
public_addr = 192.168.55.16
Code:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class ssd
device 1 osd.1 class ssd
device 2 osd.2 class ssd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host Kamino04 {
id -3 # do not change unnecessarily
id -4 class ssd # do not change unnecessarily
# weight 1.86299
alg straw2
hash 0 # rjenkins1
item osd.0 weight 1.86299
}
host Kamino05 {
id -5 # do not change unnecessarily
id -6 class ssd # do not change unnecessarily
# weight 1.86299
alg straw2
hash 0 # rjenkins1
item osd.1 weight 1.86299
}
host Kamino06 {
id -7 # do not change unnecessarily
id -8 class ssd # do not change unnecessarily
# weight 1.86299
alg straw2
hash 0 # rjenkins1
item osd.2 weight 1.86299
}
root default {
id -1 # do not change unnecessarily
id -2 class ssd # do not change unnecessarily
# weight 5.58897
alg straw2
hash 0 # rjenkins1
item Kamino04 weight 1.86299
item Kamino05 weight 1.86299
item Kamino06 weight 1.86299
}
# rules
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush mapI am very grateful for any input.
PS: Yes, I am aware that 3 nodes are not enough to operate Ceph with full fault tolerance.
Attachments
Last edited: