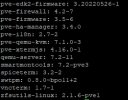
Hmm okay. So if you edit the pool and enable the "Advanced" checkbox next to the OK buttons, do you have a target_ratio set? If not, please do so, a "1" should be plenty fine. The .mgr pool can be ignored as it will not take ip any significant amount of space.
If the pool does not have any target_ratio set, then the autoscaler can only take the currently used space of the pool. I assume that it will recommend double the current number of PGs.
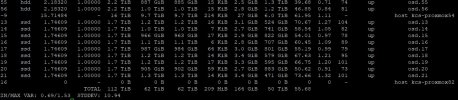
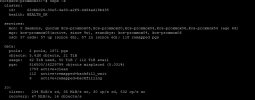
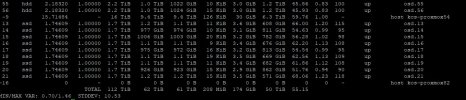
Looking through the list of OSDs more closely, I realize that you only have 2 Nodes that contain HDD OSDs and 5 with SSDs (correct me if I am wrong).
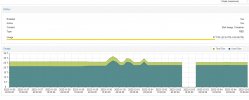
The number of OSDs varies quite a bit between the nodes. This means, that some nodes get quite a bit more traffic as they store more data than others. This can be seen in the "weight" column of the
ceph osd df tree output.
The idea is, to create two rules, one targeting HDDs, one SSDs and assign each rule to one pool. Then you would have a fast SSD pool and a slow HDD pool and can place the disk images as you need.
Since only two nodes contain HDD OSDs, it doesn't really make sense to create two pools, as you would usually want to have a size/min_size of 3/2. But that means, that you would need at least 3 nodes with OSDs of that device class.
So for now, you will see a mixed bag regarding the performance of the cluster, depending on where the data you want to access is stored.
Regarding the full problem: Please set a target ratio for the pool "ceph-vm" and if the autoscaler then recommends 2048 PGs, set it to that. It won't do it automatically as it is only a change by a factor of 2.
This might help already to redistribute the data more evenly.
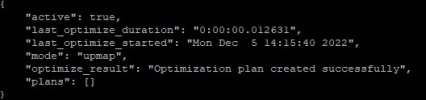
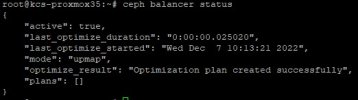
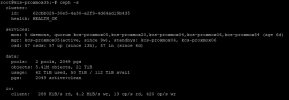
Additionally, keep an eye on the balancer. If it is done, you should see it returning this:
Code:
"optimize_result": "Unable to find further optimization, or pool(s) pg_num is decreasing, or distribution is already perfect",