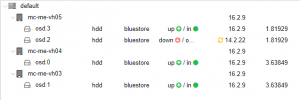
Code:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host mc-me-vh04 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 3.638
alg straw2
hash 0 # rjenkins1
item osd.0 weight 3.638
}
host mc-me-vh03 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 3.638
alg straw2
hash 0 # rjenkins1
item osd.1 weight 3.638
}
host mc-me-vh05 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 3.639
alg straw2
hash 0 # rjenkins1
item osd.2 weight 1.819
item osd.3 weight 1.819
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 10.916
alg straw2
hash 0 # rjenkins1
item mc-me-vh04 weight 3.638
item mc-me-vh03 weight 3.638
item mc-me-vh05 weight 3.639
}
host mc-me-vh06 {
id -9 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map