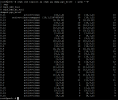
I have a 3 node ceph cluster setup containing no data just now. I have two RBD pools, one is a replicated pool dedicated to only SSD's and the other is an erasure coded pool containing only spinning disk hardware. The erasure coded pool is setup to use the replicated pool for its meta data. Ceph status overall is Healthy-OK with 62 PG's that indicate Active+Clean (which I understand to be a healthy status for a PG) however 3 PG's report a status of Active+Clean+Remapped. All 13 OSD's are in and up.
I understood from what I have read that remapping can occur from time to time however to expect it to resolve to Active+Clean. I have left this for several days now and for a cluster containing no data I would have expected that remapped status to change by now. Looking for guidance as to how to troubleshoot and correct whatever may be causing the +remapped status from resolving.
I understood from what I have read that remapping can occur from time to time however to expect it to resolve to Active+Clean. I have left this for several days now and for a cluster containing no data I would have expected that remapped status to change by now. Looking for guidance as to how to troubleshoot and correct whatever may be causing the +remapped status from resolving.