Hi all,
I am a new beginner proxmox user and have just setup our first small data centre for our business running 3 VMs on a 3 node cluster.
I have setup Ceph shared storage and enabled HA for my VMs which seems to be working fine. However I have one error which I cannot figure out.
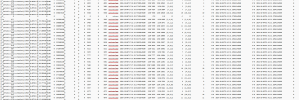
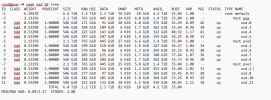
I have 4 1Tb HDD on each server along with 2 480Gb SSD. My ceph osds have been configured as below on each node.
OSD 1: 500Gb partition of HDD 1 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 2: 500Gb partition of HDD 2 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 3: 500Gb partition of HDD 3 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 4: 500Gb partition of HDD 4 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
The problem is ceph shows health warning but is full green circle with one grey part. It says 1 PG status is unknowns.
How do I troubleshoot such an error? I think this is the only issue I have across my configuration currently. The ceph storage pool is also working well with all my vms now moved to it.
Any help would be much appreciated.
I am a new beginner proxmox user and have just setup our first small data centre for our business running 3 VMs on a 3 node cluster.
I have setup Ceph shared storage and enabled HA for my VMs which seems to be working fine. However I have one error which I cannot figure out.
I have 4 1Tb HDD on each server along with 2 480Gb SSD. My ceph osds have been configured as below on each node.
OSD 1: 500Gb partition of HDD 1 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 2: 500Gb partition of HDD 2 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 3: 500Gb partition of HDD 3 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
OSD 4: 500Gb partition of HDD 4 and 80Gb of SSD 1 as the DB disk and 80Gb of SSD 2 as the WAL disk.
The problem is ceph shows health warning but is full green circle with one grey part. It says 1 PG status is unknowns.
How do I troubleshoot such an error? I think this is the only issue I have across my configuration currently. The ceph storage pool is also working well with all my vms now moved to it.
Any help would be much appreciated.


")