[SOLVED] Ceph OSD high latency on certain node
- Thread starter ethaniel86
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

>Are those two the only ones with 4x OSDs?
Yes it is.
What model are these OSDs?
node 6
Initially 4 x S4510 later switched two to Samsung SSD.
2 x Intel S4510 SSD
2 x Samsung PM863 SSD
node 7
4 x Intel S4510 SSD
root@px-sg1-n7:~# hdparm -tT /dev/sdb [Intel S4510]
/dev/sdb:
Timing cached reads: 11250 MB in 2.00 seconds = 5636.02 MB/sec
Timing buffered disk reads: 146 MB in 3.25 seconds = 44.98 MB/sec
root@px-sg1-n7:~# hdparm -tT /dev/sdc [Samsung PM863]
/dev/sdc:
Timing cached reads: 21090 MB in 1.99 seconds = 10572.80 MB/sec
Timing buffered disk reads: 8 MB in 3.25 seconds = 2.46 MB/sec
The weird thing is before added as OSD the benchmark is completely normal able to get >300MB/s but getting significant performance drop when added as OSD.
CEPH on 10Gb network.
root@px-sg1-n7:~# ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS TYPE NAME
-1 18.77379 - 18.8TiB 10.5TiB 8.27TiB 55.97 1.00 - root default
-3 2.18300 - 2.18TiB 1.23TiB 980GiB 56.16 1.00 - host [node 1]
0 ssd 0.43660 1.00000 447GiB 238GiB 209GiB 53.24 0.95 34 osd.0
1 ssd 0.87320 1.00000 894GiB 421GiB 473GiB 47.09 0.84 60 osd.1
2 ssd 0.87320 1.00000 894GiB 596GiB 298GiB 66.70 1.19 85 osd.2
-5 2.18300 - 2.18TiB 1.29TiB 919GiB 58.89 1.05 - host [node 2]
3 ssd 0.43660 1.00000 447GiB 216GiB 231GiB 48.43 0.87 31 osd.3
4 ssd 0.87320 1.00000 894GiB 544GiB 350GiB 60.89 1.09 78 osd.4
5 ssd 0.87320 1.00000 894GiB 555GiB 339GiB 62.11 1.11 79 osd.5
-7 2.18300 - 2.18TiB 1.46TiB 736GiB 67.08 1.20 - host [node 3]
6 ssd 0.43660 1.00000 447GiB 315GiB 132GiB 70.54 1.26 45 osd.6
7 ssd 0.87320 1.00000 894GiB 670GiB 224GiB 74.92 1.34 96 osd.7
8 ssd 0.87320 1.00000 894GiB 514GiB 380GiB 57.51 1.03 73 osd.8
-9 2.61960 - 2.62TiB 1.45TiB 1.17TiB 55.50 0.99 - host [node 4]
9 ssd 0.87320 1.00000 894GiB 440GiB 455GiB 49.16 0.88 63 osd.9
10 ssd 0.87320 1.00000 894GiB 461GiB 433GiB 51.57 0.92 66 osd.10
11 ssd 0.87320 1.00000 894GiB 588GiB 306GiB 65.76 1.17 84 osd.11
-11 2.61960 - 2.62TiB 1.49TiB 1.13TiB 56.91 1.02 - host [node 5]
12 ssd 0.87320 1.00000 894GiB 492GiB 402GiB 55.01 0.98 70 osd.12
13 ssd 0.87320 1.00000 894GiB 580GiB 315GiB 64.82 1.16 83 osd.13
14 ssd 0.87320 1.00000 894GiB 455GiB 439GiB 50.90 0.91 65 osd.14
-13 3.49280 - 3.49TiB 1.90TiB 1.59TiB 54.39 0.97 - host [node 6]
15 ssd 0.87320 1.00000 894GiB 460GiB 434GiB 51.44 0.92 66 osd.15
16 ssd 0.87320 1.00000 894GiB 484GiB 410GiB 54.10 0.97 69 osd.16
17 ssd 0.87320 1.00000 894GiB 532GiB 362GiB 59.50 1.06 76 osd.17
18 ssd 0.87320 1.00000 894GiB 470GiB 424GiB 52.53 0.94 67 osd.18
-15 3.49280 - 3.49TiB 1.69TiB 1.81TiB 48.30 0.86 - host [node 7]
19 ssd 0.87320 1.00000 894GiB 392GiB 502GiB 43.80 0.78 56 osd.19
20 ssd 0.87320 1.00000 894GiB 395GiB 499GiB 44.18 0.79 56 osd.20
21 ssd 0.87320 1.00000 894GiB 441GiB 453GiB 49.33 0.88 63 osd.21
22 ssd 0.87320 1.00000 894GiB 500GiB 395GiB 55.87 1.00 71 osd.22
TOTAL 18.8TiB 10.5TiB 8.27TiB 55.97
MIN/MAX VAR: 0.78/1.34 STDDEV: 8.18
Yes it is.
What model are these OSDs?
node 6
Initially 4 x S4510 later switched two to Samsung SSD.
2 x Intel S4510 SSD
2 x Samsung PM863 SSD
node 7
4 x Intel S4510 SSD
root@px-sg1-n7:~# hdparm -tT /dev/sdb [Intel S4510]
/dev/sdb:
Timing cached reads: 11250 MB in 2.00 seconds = 5636.02 MB/sec
Timing buffered disk reads: 146 MB in 3.25 seconds = 44.98 MB/sec
root@px-sg1-n7:~# hdparm -tT /dev/sdc [Samsung PM863]
/dev/sdc:
Timing cached reads: 21090 MB in 1.99 seconds = 10572.80 MB/sec
Timing buffered disk reads: 8 MB in 3.25 seconds = 2.46 MB/sec
The weird thing is before added as OSD the benchmark is completely normal able to get >300MB/s but getting significant performance drop when added as OSD.
CEPH on 10Gb network.
root@px-sg1-n7:~# ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS TYPE NAME
-1 18.77379 - 18.8TiB 10.5TiB 8.27TiB 55.97 1.00 - root default
-3 2.18300 - 2.18TiB 1.23TiB 980GiB 56.16 1.00 - host [node 1]
0 ssd 0.43660 1.00000 447GiB 238GiB 209GiB 53.24 0.95 34 osd.0
1 ssd 0.87320 1.00000 894GiB 421GiB 473GiB 47.09 0.84 60 osd.1
2 ssd 0.87320 1.00000 894GiB 596GiB 298GiB 66.70 1.19 85 osd.2
-5 2.18300 - 2.18TiB 1.29TiB 919GiB 58.89 1.05 - host [node 2]
3 ssd 0.43660 1.00000 447GiB 216GiB 231GiB 48.43 0.87 31 osd.3
4 ssd 0.87320 1.00000 894GiB 544GiB 350GiB 60.89 1.09 78 osd.4
5 ssd 0.87320 1.00000 894GiB 555GiB 339GiB 62.11 1.11 79 osd.5
-7 2.18300 - 2.18TiB 1.46TiB 736GiB 67.08 1.20 - host [node 3]
6 ssd 0.43660 1.00000 447GiB 315GiB 132GiB 70.54 1.26 45 osd.6
7 ssd 0.87320 1.00000 894GiB 670GiB 224GiB 74.92 1.34 96 osd.7
8 ssd 0.87320 1.00000 894GiB 514GiB 380GiB 57.51 1.03 73 osd.8
-9 2.61960 - 2.62TiB 1.45TiB 1.17TiB 55.50 0.99 - host [node 4]
9 ssd 0.87320 1.00000 894GiB 440GiB 455GiB 49.16 0.88 63 osd.9
10 ssd 0.87320 1.00000 894GiB 461GiB 433GiB 51.57 0.92 66 osd.10
11 ssd 0.87320 1.00000 894GiB 588GiB 306GiB 65.76 1.17 84 osd.11
-11 2.61960 - 2.62TiB 1.49TiB 1.13TiB 56.91 1.02 - host [node 5]
12 ssd 0.87320 1.00000 894GiB 492GiB 402GiB 55.01 0.98 70 osd.12
13 ssd 0.87320 1.00000 894GiB 580GiB 315GiB 64.82 1.16 83 osd.13
14 ssd 0.87320 1.00000 894GiB 455GiB 439GiB 50.90 0.91 65 osd.14
-13 3.49280 - 3.49TiB 1.90TiB 1.59TiB 54.39 0.97 - host [node 6]
15 ssd 0.87320 1.00000 894GiB 460GiB 434GiB 51.44 0.92 66 osd.15
16 ssd 0.87320 1.00000 894GiB 484GiB 410GiB 54.10 0.97 69 osd.16
17 ssd 0.87320 1.00000 894GiB 532GiB 362GiB 59.50 1.06 76 osd.17
18 ssd 0.87320 1.00000 894GiB 470GiB 424GiB 52.53 0.94 67 osd.18
-15 3.49280 - 3.49TiB 1.69TiB 1.81TiB 48.30 0.86 - host [node 7]
19 ssd 0.87320 1.00000 894GiB 392GiB 502GiB 43.80 0.78 56 osd.19
20 ssd 0.87320 1.00000 894GiB 395GiB 499GiB 44.18 0.79 56 osd.20
21 ssd 0.87320 1.00000 894GiB 441GiB 453GiB 49.33 0.88 63 osd.21
22 ssd 0.87320 1.00000 894GiB 500GiB 395GiB 55.87 1.00 71 osd.22
TOTAL 18.8TiB 10.5TiB 8.27TiB 55.97
MIN/MAX VAR: 0.78/1.34 STDDEV: 8.18
Last edited:
You have a imbalance in your ceph cluster, probably because of adding OSDs later on. You can try to balance it out with one of the below commands. There is also a test command to get the proposed modifications (see the link).
http://docs.ceph.com/docs/luminous/rados/operations/control/?highlight=bench#osd-subsystem
And AFAIC, you need more PGs, as traget count for a OSD is 100.
https://ceph.com/pgcalc/
EDIT: Did you configure any crush rules, besides the default?
Code:
ceph osd reweight-by-utilization [threshold]
ceph osd reweight-by-pg [threshold]And AFAIC, you need more PGs, as traget count for a OSD is 100.
https://ceph.com/pgcalc/
EDIT: Did you configure any crush rules, besides the default?
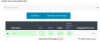
About the screenshot. If I counted right then you have 23x OSDs and the target should be 100 PGs per OSD, the next power of 2 will be taken from it. If you don't intent to expand your cluster twice the size in the near future, then it should be set to a 100. Also if you only have one pool then that pool will use 100% of the space available, so %Data should be set to 100%.
http://docs.ceph.com/docs/luminous/...nt-groups/#set-the-number-of-placement-groups
Yes, then you can increase the PG number of your pool(s). If you have more than one pool, then you need to redo the calculation.I am using PG 512. According to calculator i should make it 1024? Do you have doc on how to increase PG the proper way?
http://docs.ceph.com/docs/luminous/...nt-groups/#set-the-number-of-placement-groups
I have increased PG/PGP to 1024, enabled ceph balancer, somehow only the specific(latest addition) two node still getting high latency. Any other recommendation? Radoes bench looks slow
# rados bench -p rbd-vm 10 write
hints = 1
Maintaining 16 concurrent writes of 4194304 bytes to objects of size 4194304 for up to 10 seconds or 0 objects
Object prefix: benchmark_data_px-sg1-n1_3267236
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 62 46 183.987 184 0.0315373 0.169385
2 16 91 75 149.982 116 0.0694516 0.304366
3 16 139 123 163.979 192 0.682695 0.312907
4 16 183 167 166.979 176 0.0738586 0.345967
5 16 209 193 154.38 104 0.0304566 0.384892
6 16 241 225 149.98 128 0.0230194 0.373243
7 16 279 263 150.266 152 0.0206312 0.381853
8 16 318 302 150.981 156 0.0232578 0.380654
9 16 368 352 156.424 200 0.0297577 0.393897
10 16 396 380 151.98 112 0.917137 0.407392
11 15 397 382 138.891 8 0.435091 0.4069
Total time run: 11.664937
Total writes made: 397
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 136.134
Stddev Bandwidth: 54.9062
Max bandwidth (MB/sec): 200
Min bandwidth (MB/sec): 8
Average IOPS: 34
Stddev IOPS: 13
Max IOPS: 50
Min IOPS: 2
Average Latency(s): 0.465855
Stddev Latency(s): 0.584395
Max latency(s): 2.11074
Min latency(s): 0.0206312
Cleaning up (deleting benchmark objects)
Removed 397 objects
Clean up completed and total clean up time :4.002566
# rados bench -p rbd-vm 10 write
hints = 1
Maintaining 16 concurrent writes of 4194304 bytes to objects of size 4194304 for up to 10 seconds or 0 objects
Object prefix: benchmark_data_px-sg1-n1_3267236
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 62 46 183.987 184 0.0315373 0.169385
2 16 91 75 149.982 116 0.0694516 0.304366
3 16 139 123 163.979 192 0.682695 0.312907
4 16 183 167 166.979 176 0.0738586 0.345967
5 16 209 193 154.38 104 0.0304566 0.384892
6 16 241 225 149.98 128 0.0230194 0.373243
7 16 279 263 150.266 152 0.0206312 0.381853
8 16 318 302 150.981 156 0.0232578 0.380654
9 16 368 352 156.424 200 0.0297577 0.393897
10 16 396 380 151.98 112 0.917137 0.407392
11 15 397 382 138.891 8 0.435091 0.4069
Total time run: 11.664937
Total writes made: 397
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 136.134
Stddev Bandwidth: 54.9062
Max bandwidth (MB/sec): 200
Min bandwidth (MB/sec): 8
Average IOPS: 34
Stddev IOPS: 13
Max IOPS: 50
Min IOPS: 2
Average Latency(s): 0.465855
Stddev Latency(s): 0.584395
Max latency(s): 2.11074
Min latency(s): 0.0206312
Cleaning up (deleting benchmark objects)
Removed 397 objects
Clean up completed and total clean up time :4.002566
root@node-7:~# pveversion -v
proxmox-ve: 5.4-1 (running kernel: 4.15.18-12-pve)
pve-manager: 5.4-3 (running version: 5.4-3/0a6eaa62)
pve-kernel-4.15: 5.3-3
pve-kernel-4.15.18-12-pve: 4.15.18-35
ceph: 12.2.12-pve1
corosync: 2.4.4-pve1
criu: 2.11.1-1~bpo90
glusterfs-client: 3.8.8-1
ksm-control-daemon: 1.2-2
libjs-extjs: 6.0.1-2
libpve-access-control: 5.1-8
libpve-apiclient-perl: 2.0-5
libpve-common-perl: 5.0-50
libpve-guest-common-perl: 2.0-20
libpve-http-server-perl: 2.0-13
libpve-storage-perl: 5.0-41
libqb0: 1.0.3-1~bpo9
lvm2: 2.02.168-pve6
lxc-pve: 3.1.0-3
lxcfs: 3.0.3-pve1
novnc-pve: 1.0.0-3
proxmox-widget-toolkit: 1.0-25
pve-cluster: 5.0-36
pve-container: 2.0-37
pve-docs: 5.4-2
pve-edk2-firmware: 1.20190312-1
pve-firewall: 3.0-19
pve-firmware: 2.0-6
pve-ha-manager: 2.0-9
pve-i18n: 1.1-4
pve-libspice-server1: 0.14.1-2
pve-qemu-kvm: 2.12.1-3
pve-xtermjs: 3.12.0-1
qemu-server: 5.0-50
smartmontools: 6.5+svn4324-1
spiceterm: 3.0-5
vncterm: 1.5-3
zfsutils-linux: 0.7.13-pve1~bpo2
We have 5.3 and 5.4 in this cluster.
>>And try to restart the OSDs in question to see if the latency goes back.
Yes, also tried reboot host.
proxmox-ve: 5.4-1 (running kernel: 4.15.18-12-pve)
pve-manager: 5.4-3 (running version: 5.4-3/0a6eaa62)
pve-kernel-4.15: 5.3-3
pve-kernel-4.15.18-12-pve: 4.15.18-35
ceph: 12.2.12-pve1
corosync: 2.4.4-pve1
criu: 2.11.1-1~bpo90
glusterfs-client: 3.8.8-1
ksm-control-daemon: 1.2-2
libjs-extjs: 6.0.1-2
libpve-access-control: 5.1-8
libpve-apiclient-perl: 2.0-5
libpve-common-perl: 5.0-50
libpve-guest-common-perl: 2.0-20
libpve-http-server-perl: 2.0-13
libpve-storage-perl: 5.0-41
libqb0: 1.0.3-1~bpo9
lvm2: 2.02.168-pve6
lxc-pve: 3.1.0-3
lxcfs: 3.0.3-pve1
novnc-pve: 1.0.0-3
proxmox-widget-toolkit: 1.0-25
pve-cluster: 5.0-36
pve-container: 2.0-37
pve-docs: 5.4-2
pve-edk2-firmware: 1.20190312-1
pve-firewall: 3.0-19
pve-firmware: 2.0-6
pve-ha-manager: 2.0-9
pve-i18n: 1.1-4
pve-libspice-server1: 0.14.1-2
pve-qemu-kvm: 2.12.1-3
pve-xtermjs: 3.12.0-1
qemu-server: 5.0-50
smartmontools: 6.5+svn4324-1
spiceterm: 3.0-5
vncterm: 1.5-3
zfsutils-linux: 0.7.13-pve1~bpo2
We have 5.3 and 5.4 in this cluster.
>>And try to restart the OSDs in question to see if the latency goes back.
Yes, also tried reboot host.
suspect due to LSI 3108 controller. The two high latency nodes with raid1 OS, 4xSSD(JBOD) mode. will gather more hardware info and post here.