Hi I have 4 nodes of pves and they are quite identical in configs.
each of them have has 6x drives that.
but I have noticed that one drive failed and as the vms kept writing data it became near full
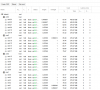
here is the output of ceph -s
root@pve2:~# ceph -s
cluster:
id: a9926f78-4366-4be5-a77c-7db26a419e86
health: HEALTH_ERR
Reduced data availability: 434 pgs inactive, 434 pgs peering
920 stuck requests are blocked > 4096 sec. Implicated osds 6,7,8,9,10,12,20,21,22,23
services:
mon: 4 daemons, quorum pve1,pve2,pve3,pve4
mgr: pve1(active), standbys: pve2, pve4, pve3
osd: 24 osds: 23 up, 23 in; 15 remapped pgs
data:
pools: 4 pools, 832 pgs
objects: 419k objects, 1575 GB
usage: 4792 GB used, 2003 GB / 6795 GB avail
pgs: 52.163% pgs not active
419 peering
398 active+clean
15 remapped+peering
as you can see we do have lots of available space but I dont know what went wrong. is it the failed drive or what exactly?
is there a way to get things re sorted??
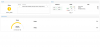
here is a extract of latest logs
2020-01-27 07:00:00.000267 mon.pve1 mon.0 10.10.10.11:6789/0 7895062 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 08:00:00.000180 mon.pve1 mon.0 10.10.10.11:6789/0 7897154 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 09:00:00.000129 mon.pve1 mon.0 10.10.10.11:6789/0 7899344 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 09:58:49.569805 mon.pve1 mon.0 10.10.10.11:6789/0 7901486 : cluster [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 18 (REQUEST_SLOW)
2020-01-27 09:58:54.618459 mon.pve1 mon.0 10.10.10.11:6789/0 7901509 : cluster [WRN] Health check update: 2 slow requests are blocked > 32 sec. Implicated osds 10,18 (REQUEST_SLOW)
2020-01-27 09:59:11.953819 mon.pve1 mon.0 10.10.10.11:6789/0 7901526 : cluster [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 8,10,18 (REQUEST_SLOW)
2020-01-27 09:59:34.272930 mon.pve1 mon.0 10.10.10.11:6789/0 7901543 : cluster [WRN] Health check update: 4 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21 (REQUEST_SLOW)
2020-01-27 10:00:00.000200 mon.pve1 mon.0 10.10.10.11:6789/0 7901568 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull; 4 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21
2020-01-27 10:00:10.700322 mon.pve1 mon.0 10.10.10.11:6789/0 7901578 : cluster [WRN] Health check update: 6 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21 (REQUEST_SLOW)
2020-01-27 10:00:24.757803 mon.pve1 mon.0 10.10.10.11:6789/0 7901594 : cluster [WRN] Health check update: 7 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21,23 (REQUEST_SLOW)
2020-01-27 10:00:44.928742 mon.pve1 mon.0 10.10.10.11:6789/0 7901605 : cluster [WRN] Health check update: 12 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:00:51.428743 mon.pve1 mon.0 10.10.10.11:6789/0 7901610 : cluster [WRN] Health check update: 14 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:00:58.856057 mon.pve1 mon.0 10.10.10.11:6789/0 7901613 : cluster [WRN] Health check update: 17 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:01:33.662488 mon.pve1 mon.0 10.10.10.11:6789/0 7901648 : cluster [WRN] Health check update: 18 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:01:51.480059 mon.pve1 mon.0 10.10.10.11:6789/0 7901663 : cluster [WRN] Health check update: 20 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:02:56.537558 mon.pve1 mon.0 10.10.10.11:6789/0 7901701 : cluster [WRN] Health check update: 22 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:20.659258 mon.pve1 mon.0 10.10.10.11:6789/0 7901721 : cluster [WRN] Health check update: 23 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:29.051215 mon.pve1 mon.0 10.10.10.11:6789/0 7901731 : cluster [WRN] Health check update: 24 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:50.807869 mon.pve1 mon.0 10.10.10.11:6789/0 7901752 : cluster [WRN] Health check update: 26 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:04:35.452388 mon.pve1 mon.0 10.10.10.11:6789/0 7901787 : cluster [WRN] Health check update: 27 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:04:51.427521 mon.pve1 mon.0 10.10.10.11:6789/0 7901798 : cluster [WRN] Health check update: 29 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:33.483019 mon.pve1 mon.0 10.10.10.11:6789/0 7901835 : cluster [WRN] Health check update: 30 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:39.786841 mon.pve1 mon.0 10.10.10.11:6789/0 7901841 : cluster [WRN] Health check update: 35 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:51.889322 mon.pve1 mon.0 10.10.10.11:6789/0 7901855 : cluster [WRN] Health check update: 37 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:06:50.338031 mon.pve1 mon.0 10.10.10.11:6789/0 7901897 : cluster [WRN] Health check update: 39 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:07:28.856721 mon.pve1 mon.0 10.10.10.11:6789/0 7901922 : cluster [WRN] Health check update: 40 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:07:50.854370 mon.pve1 mon.0 10.10.10.11:6789/0 7901938 : cluster [WRN] Health check update: 42 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:17.174128 mon.pve1 mon.0 10.10.10.11:6789/0 7901955 : cluster [WRN] Health check update: 43 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:39.751586 mon.pve1 mon.0 10.10.10.11:6789/0 7901972 : cluster [WRN] Health check update: 44 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:51.876339 mon.pve1 mon.0 10.10.10.11:6789/0 7901982 : cluster [WRN] Health check update: 46 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:09:28.717695 mon.pve1 mon.0 10.10.10.11:6789/0 7902012 : cluster [WRN] Health check update: 47 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:09:52.040808 mon.pve1 mon.0 10.10.10.11:6789/0 7902032 : cluster [WRN] Health check update: 49 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:24.348908 mon.pve1 mon.0 10.10.10.11:6789/0 7902058 : cluster [WRN] Health check update: 50 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:30.408543 mon.pve1 mon.0 10.10.10.11:6789/0 7902060 : cluster [WRN] Health check update: 51 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:51.358077 mon.pve1 mon.0 10.10.10.11:6789/0 7902077 : cluster [WRN] Health check update: 53 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:58.912309 mon.pve1 mon.0 10.10.10.11:6789/0 7902079 : cluster [WRN] Health check update: 60 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:04.877804 mon.pve1 mon.0 10.10.10.11:6789/0 7902088 : cluster [WRN] Health check update: 61 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:25.444557 mon.pve1 mon.0 10.10.10.11:6789/0 7902103 : cluster [WRN] Health check update: 63 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:34.880921 mon.pve1 mon.0 10.10.10.11:6789/0 7902110 : cluster [WRN] Health check update: 64 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:51.527392 mon.pve1 mon.0 10.10.10.11:6789/0 7902124 : cluster [WRN] Health check update: 66 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:59.883620 mon.pve1 mon.0 10.10.10.11:6789/0 7902135 : cluster [WRN] Health check update: 67 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:12:10.056527 mon.pve1 mon.0 10.10.10.11:6789/0 7902144 : cluster [WRN] Health check update: 68 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
each of them have has 6x drives that.
but I have noticed that one drive failed and as the vms kept writing data it became near full
here is the output of ceph -s
root@pve2:~# ceph -s
cluster:
id: a9926f78-4366-4be5-a77c-7db26a419e86
health: HEALTH_ERR
Reduced data availability: 434 pgs inactive, 434 pgs peering
920 stuck requests are blocked > 4096 sec. Implicated osds 6,7,8,9,10,12,20,21,22,23
services:
mon: 4 daemons, quorum pve1,pve2,pve3,pve4
mgr: pve1(active), standbys: pve2, pve4, pve3
osd: 24 osds: 23 up, 23 in; 15 remapped pgs
data:
pools: 4 pools, 832 pgs
objects: 419k objects, 1575 GB
usage: 4792 GB used, 2003 GB / 6795 GB avail
pgs: 52.163% pgs not active
419 peering
398 active+clean
15 remapped+peering
as you can see we do have lots of available space but I dont know what went wrong. is it the failed drive or what exactly?
is there a way to get things re sorted??
here is a extract of latest logs
2020-01-27 07:00:00.000267 mon.pve1 mon.0 10.10.10.11:6789/0 7895062 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 08:00:00.000180 mon.pve1 mon.0 10.10.10.11:6789/0 7897154 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 09:00:00.000129 mon.pve1 mon.0 10.10.10.11:6789/0 7899344 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull
2020-01-27 09:58:49.569805 mon.pve1 mon.0 10.10.10.11:6789/0 7901486 : cluster [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 18 (REQUEST_SLOW)
2020-01-27 09:58:54.618459 mon.pve1 mon.0 10.10.10.11:6789/0 7901509 : cluster [WRN] Health check update: 2 slow requests are blocked > 32 sec. Implicated osds 10,18 (REQUEST_SLOW)
2020-01-27 09:59:11.953819 mon.pve1 mon.0 10.10.10.11:6789/0 7901526 : cluster [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 8,10,18 (REQUEST_SLOW)
2020-01-27 09:59:34.272930 mon.pve1 mon.0 10.10.10.11:6789/0 7901543 : cluster [WRN] Health check update: 4 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21 (REQUEST_SLOW)
2020-01-27 10:00:00.000200 mon.pve1 mon.0 10.10.10.11:6789/0 7901568 : cluster [WRN] overall HEALTH_WARN 1 backfillfull osd(s); 1 nearfull osd(s); 4 pool(s) backfillfull; 4 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21
2020-01-27 10:00:10.700322 mon.pve1 mon.0 10.10.10.11:6789/0 7901578 : cluster [WRN] Health check update: 6 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21 (REQUEST_SLOW)
2020-01-27 10:00:24.757803 mon.pve1 mon.0 10.10.10.11:6789/0 7901594 : cluster [WRN] Health check update: 7 slow requests are blocked > 32 sec. Implicated osds 8,10,18,21,23 (REQUEST_SLOW)
2020-01-27 10:00:44.928742 mon.pve1 mon.0 10.10.10.11:6789/0 7901605 : cluster [WRN] Health check update: 12 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:00:51.428743 mon.pve1 mon.0 10.10.10.11:6789/0 7901610 : cluster [WRN] Health check update: 14 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:00:58.856057 mon.pve1 mon.0 10.10.10.11:6789/0 7901613 : cluster [WRN] Health check update: 17 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:01:33.662488 mon.pve1 mon.0 10.10.10.11:6789/0 7901648 : cluster [WRN] Health check update: 18 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:01:51.480059 mon.pve1 mon.0 10.10.10.11:6789/0 7901663 : cluster [WRN] Health check update: 20 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:02:56.537558 mon.pve1 mon.0 10.10.10.11:6789/0 7901701 : cluster [WRN] Health check update: 22 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:20.659258 mon.pve1 mon.0 10.10.10.11:6789/0 7901721 : cluster [WRN] Health check update: 23 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:29.051215 mon.pve1 mon.0 10.10.10.11:6789/0 7901731 : cluster [WRN] Health check update: 24 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:03:50.807869 mon.pve1 mon.0 10.10.10.11:6789/0 7901752 : cluster [WRN] Health check update: 26 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:04:35.452388 mon.pve1 mon.0 10.10.10.11:6789/0 7901787 : cluster [WRN] Health check update: 27 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:04:51.427521 mon.pve1 mon.0 10.10.10.11:6789/0 7901798 : cluster [WRN] Health check update: 29 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:33.483019 mon.pve1 mon.0 10.10.10.11:6789/0 7901835 : cluster [WRN] Health check update: 30 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:39.786841 mon.pve1 mon.0 10.10.10.11:6789/0 7901841 : cluster [WRN] Health check update: 35 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:05:51.889322 mon.pve1 mon.0 10.10.10.11:6789/0 7901855 : cluster [WRN] Health check update: 37 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:06:50.338031 mon.pve1 mon.0 10.10.10.11:6789/0 7901897 : cluster [WRN] Health check update: 39 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:07:28.856721 mon.pve1 mon.0 10.10.10.11:6789/0 7901922 : cluster [WRN] Health check update: 40 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:07:50.854370 mon.pve1 mon.0 10.10.10.11:6789/0 7901938 : cluster [WRN] Health check update: 42 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:17.174128 mon.pve1 mon.0 10.10.10.11:6789/0 7901955 : cluster [WRN] Health check update: 43 slow requests are blocked > 32 sec. Implicated osds 8,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:39.751586 mon.pve1 mon.0 10.10.10.11:6789/0 7901972 : cluster [WRN] Health check update: 44 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:08:51.876339 mon.pve1 mon.0 10.10.10.11:6789/0 7901982 : cluster [WRN] Health check update: 46 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:09:28.717695 mon.pve1 mon.0 10.10.10.11:6789/0 7902012 : cluster [WRN] Health check update: 47 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:09:52.040808 mon.pve1 mon.0 10.10.10.11:6789/0 7902032 : cluster [WRN] Health check update: 49 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:24.348908 mon.pve1 mon.0 10.10.10.11:6789/0 7902058 : cluster [WRN] Health check update: 50 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:30.408543 mon.pve1 mon.0 10.10.10.11:6789/0 7902060 : cluster [WRN] Health check update: 51 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:51.358077 mon.pve1 mon.0 10.10.10.11:6789/0 7902077 : cluster [WRN] Health check update: 53 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:10:58.912309 mon.pve1 mon.0 10.10.10.11:6789/0 7902079 : cluster [WRN] Health check update: 60 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:04.877804 mon.pve1 mon.0 10.10.10.11:6789/0 7902088 : cluster [WRN] Health check update: 61 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:25.444557 mon.pve1 mon.0 10.10.10.11:6789/0 7902103 : cluster [WRN] Health check update: 63 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:34.880921 mon.pve1 mon.0 10.10.10.11:6789/0 7902110 : cluster [WRN] Health check update: 64 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:51.527392 mon.pve1 mon.0 10.10.10.11:6789/0 7902124 : cluster [WRN] Health check update: 66 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:11:59.883620 mon.pve1 mon.0 10.10.10.11:6789/0 7902135 : cluster [WRN] Health check update: 67 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)
2020-01-27 10:12:10.056527 mon.pve1 mon.0 10.10.10.11:6789/0 7902144 : cluster [WRN] Health check update: 68 slow requests are blocked > 32 sec. Implicated osds 8,9,10,18,20,21,23 (REQUEST_SLOW)