Hi everybody how are you,
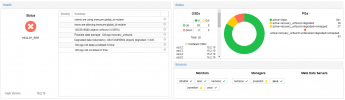
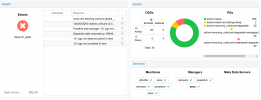
Today after updating proxmox and restarting OSDs it began to create errors in which different SSDs are involved that we use as cache in a hybrid storage with SSD cache + HDD storage.
If I reset the OSDs involved I don't get any improvement.
Some help?
I thank you in advance,
Greetings.
Today after updating proxmox and restarting OSDs it began to create errors in which different SSDs are involved that we use as cache in a hybrid storage with SSD cache + HDD storage.
If I reset the OSDs involved I don't get any improvement.
Some help?
I thank you in advance,
Greetings.