I've been having issues with a node so I added another one, made a cluster and figured I'd move from old to new.
Each node- 6 core/ 12 thread NUC, 64GB RAM, one has 3x 2TB NVMe in RAIDZ-1, the 'bad' node has 2x 2TB NVMe in ZFS mirror
Both have 2x 1gb-e and a PCI 2 port 10Gb-e card (Intel).
Management on 1Gb-e, all VMs on 10Gb-e
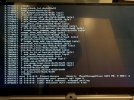
It starts copying, lasts around 5 minutes and then-
This crashes the old node, cluster, everything. Requires a manual poke to reboot.
Originally I thought that a ZFS error may be responsible (due to an earlier crash) but now not sure
I've also tried shutting down a VM and migrating it cold, same issue.
tried using gdisk to fix the partition error, same issue
tried setting up a Proxmox backup server, haven't got it working yet
Here are the results of my latest attempt at cold migration-
I'm going nuts- where do I start looking for clues please?
Each node- 6 core/ 12 thread NUC, 64GB RAM, one has 3x 2TB NVMe in RAIDZ-1, the 'bad' node has 2x 2TB NVMe in ZFS mirror
Both have 2x 1gb-e and a PCI 2 port 10Gb-e card (Intel).
Management on 1Gb-e, all VMs on 10Gb-e
It starts copying, lasts around 5 minutes and then-
This crashes the old node, cluster, everything. Requires a manual poke to reboot.
Originally I thought that a ZFS error may be responsible (due to an earlier crash) but now not sure
I've also tried shutting down a VM and migrating it cold, same issue.
tried using gdisk to fix the partition error, same issue
tried setting up a Proxmox backup server, haven't got it working yet
Here are the results of my latest attempt at cold migration-
2022-05-06 23:18:10 23:18:10 29.0G rpool/data/vm-101-disk-1@__migration__
2022-05-06 23:18:11 warning: cannot send 'rpool/data/vm-101-disk-1@__migration__': Input/output error
2022-05-06 23:18:12 cannot receive new filesystem stream: checksum mismatch
2022-05-06 23:18:12 cannot open 'rpool/data/vm-101-disk-3': dataset does not exist
2022-05-06 23:18:12 command 'zfs recv -F -- rpool/data/vm-101-disk-3' failed: exit code 1
send/receive failed, cleaning up snapshot(s)..
2022-05-06 23:18:12 ERROR: storage migration for 'local-zfs:vm-101-disk-1' to storage 'local-zfs' failed - command 'set -o pipefail && pvesm export local-zfs:vm-101-disk-1 zfs - -with-snapshots 0 -snapshot __migration__ | /usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=pve02' root@172.20.1.20 -- pvesm import local-zfs:vm-101-disk-1 zfs - -with-snapshots 0 -snapshot __migration__ -delete-snapshot __migration__ -allow-rename 1' failed: exit code 1
2022-05-06 23:18:12 aborting phase 1 - cleanup resources
2022-05-06 23:18:13 ERROR: migration aborted (duration 00:04:36): storage migration for 'local-zfs:vm-101-disk-1' to storage 'local-zfs' failed - command 'set -o pipefail && pvesm export local-zfs:vm-101-disk-1 zfs - -with-snapshots 0 -snapshot __migration__ | /usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=pve02' root@172.20.1.20 -- pvesm import local-zfs:vm-101-disk-1 zfs - -with-snapshots 0 -snapshot __migration__ -delete-snapshot __migration__ -allow-rename 1' failed: exit code 1
TASK ERROR: migration abortedI'm going nuts- where do I start looking for clues please?