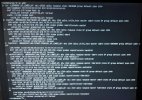
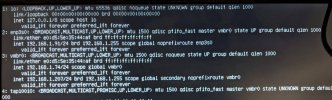
root@pharpe:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp3s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr0 state UP group default qlen 1000
link/ether e0:d5:5e:35:44:af brd ff:ff:ff:ff:ff:ff
inet 192.168.1.91/24 brd 192.168.1.255 scope global noprefixroute enp3s0
valid_lft forever preferred_lft forever
3: vmbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e0:d5:5e:35:44:af brd ff:ff:ff:ff:ff:ff
inet 192.168.1.91/24 brd 192.168.1.255 scope global noprefixroute vmbr0
valid_lft forever preferred_lft forever
4: tap100i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr0 state UNKNOWN group default qlen 1000
link/ether ce:61:44:a0:b0:ce brd ff:ff:ff:ff:ff:ff
inet 169.254.17.25/16 brd 169.254.255.255 scope global noprefixroute tap100i0
valid_lft forever preferred_lft forever
5: veth101i0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr0 state UP group default qlen 1000
link/ether fe:47:4e:35:45:7d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 169.254.31.45/16 brd 169.254.255.255 scope global noprefixroute veth101i0
valid_lft forever preferred_lft forever
6: veth102i0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr102i0 state UP group default qlen 1000
link/ether fe:b6:aa:c2:0b:70 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 169.254.189.61/16 brd 169.254.255.255 scope global noprefixroute veth102i0
valid_lft forever preferred_lft forever
7: fwbr102i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 02:29:1c:d5:b3:a5 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.181/24 brd 192.168.1.255 scope global noprefixroute fwbr102i0
valid_lft forever preferred_lft forever
8: fwpr102p0@fwln102i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr0 state UP group default qlen 1000
link/ether ce:31:8a:8b:3a:a5 brd ff:ff:ff:ff:ff:ff
inet 169.254.233.0/16 brd 169.254.255.255 scope global noprefixroute fwpr102p0
valid_lft forever preferred_lft forever
9: fwln102i0@fwpr102p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr102i0 state UP group default qlen 1000
link/ether 02:29:1c:d5:b3:a5 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.135/24 brd 192.168.1.255 scope global noprefixroute fwln102i0
valid_lft forever preferred_lft forever
10: veth104i0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr104i0 state UP group default qlen 1000
link/ether fe:d0:f8:c5:d2:5e brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet 169.254.114.219/16 brd 169.254.255.255 scope global noprefixroute veth104i0
valid_lft forever preferred_lft forever
11: fwbr104i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether da:c6:75:e5:0a:d6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.189/24 brd 192.168.1.255 scope global noprefixroute fwbr104i0
valid_lft forever preferred_lft forever
12: fwpr104p0@fwln104i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr0 state UP group default qlen 1000
link/ether 52:39:eb:db:b2:64 brd ff:ff:ff:ff:ff:ff
inet 169.254.248.110/16 brd 169.254.255.255 scope global noprefixroute fwpr104p0
valid_lft forever preferred_lft forever
13: fwln104i0@fwpr104p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr104i0 state UP group default qlen 1000
link/ether da:c6:75:e5:0a:d6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.187/24 brd 192.168.1.255 scope global noprefixroute fwln104i0
valid_lft forever preferred_lft forever