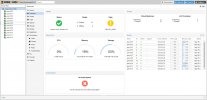
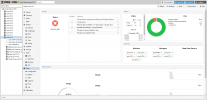
Last week my promox rack had problem with power supply. 5 servers mainboard damaged. I fixed the 3 servers but 2 servers are not back to online. Ceph storage show warning as below:
ceph -s
cluster:
id: 17fc003a-208b-4c20-82e2-c59307bd8334
health: HEALTH_WARN
Reduced data availability: 137 pgs inactive, 100 pgs down
100 pgs not deep-scrubbed in time
100 pgs not scrubbed in time
3 slow ops, oldest one blocked for 108705 sec, osd.13 has slow ops
1/5 mons down, quorum pve-tr100,pve-tr102,pve-tr106,pve-tr112
services:
mon: 5 daemons, quorum pve-tr100,pve-tr102,pve-tr106,pve-tr112 (age 29h), out of quorum: pve-tr104
mgr: pve-tr100(active, since 29h), standbys: pve-tr102, pve-tr106, pve-tr112
osd: 33 osds: 27 up (since 29h), 27 in (since 31h)
data:
pools: 1 pools, 2048 pgs
objects: 556.20k objects, 2.1 TiB
usage: 6.3 TiB used, 7.8 TiB / 14 TiB avail
pgs: 1.807% pgs unknown
4.883% pgs not active
1911 active+clean
100 down
37 unknown
ceph -s
cluster:
id: 17fc003a-208b-4c20-82e2-c59307bd8334
health: HEALTH_WARN
Reduced data availability: 137 pgs inactive, 100 pgs down
100 pgs not deep-scrubbed in time
100 pgs not scrubbed in time
3 slow ops, oldest one blocked for 108705 sec, osd.13 has slow ops
1/5 mons down, quorum pve-tr100,pve-tr102,pve-tr106,pve-tr112
services:
mon: 5 daemons, quorum pve-tr100,pve-tr102,pve-tr106,pve-tr112 (age 29h), out of quorum: pve-tr104
mgr: pve-tr100(active, since 29h), standbys: pve-tr102, pve-tr106, pve-tr112
osd: 33 osds: 27 up (since 29h), 27 in (since 31h)
data:
pools: 1 pools, 2048 pgs
objects: 556.20k objects, 2.1 TiB
usage: 6.3 TiB used, 7.8 TiB / 14 TiB avail
pgs: 1.807% pgs unknown
4.883% pgs not active
1911 active+clean
100 down
37 unknown