Hi all,
I'm experiencing a very strange problem and could really need some substantial help since I'm running out of ideas where to look for a solution to this problem:
I'm experiencing a very strange problem and could really need some substantial help since I'm running out of ideas where to look for a solution to this problem:
- I'm running a newly installed PVE, version 4.4-12 with newest upgrade installed and brand new hardware
- I'm running the system on 2 x 3GB SATA disks and a NVMe SSD 512GB
- I'm running ZFS with mirror on SATA and 256GB cache and 256GB log on the SSD
Here's Info on my ZFS:
zpool list:
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
rpool 1.81T 225G 1.59T - 10% 12% 1.00x ONLINE -
zpool status:
pool: rpool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda2 ONLINE 0 0 0
sdb2 ONLINE 0 0 0
logs
nvme0n1p1 ONLINE 0 0 0
cache
nvme0n1p2 ONLINE 0 0 0
errors: No known data errors
zfs list:
NAME USED AVAIL REFER MOUNTPOINT
rpool 233G 1.53T 96K /rpool
rpool/ROOT 3.15G 1.53T 96K /rpool/ROOT
rpool/ROOT/pve-1 3.15G 1.53T 3.15G /
rpool/data 221G 1.53T 96K /rpool/data
rpool/data/base-101-disk-1 2.49G 1.53T 2.49G -
rpool/data/subvol-100-disk-1 1.12G 10.9G 1.12G /rpool/data/subvol-100-disk-1
rpool/data/subvol-108-disk-1 2.01G 5.99G 2.01G /rpool/data/subvol-108-disk-1
rpool/data/subvol-109-disk-1 934M 19.1G 934M /rpool/data/subvol-109-disk-1
rpool/data/vm-102-disk-1 3.45G 1.53T 3.45G -
rpool/data/vm-102-disk-2 76.0G 1.53T 76.0G -
rpool/data/vm-103-disk-1 27.1G 1.53T 27.1G -
rpool/data/vm-104-disk-1 18.3G 1.53T 18.3G -
rpool/data/vm-105-disk-1 2.38G 1.53T 2.38G -
rpool/data/vm-106-disk-1 83.9G 1.53T 83.9G -
rpool/data/vm-107-disk-1 3.56G 1.53T 3.56G -
rpool/swap 8.50G 1.54T 568M -
- I'm running vzdump nightly on all VMs (LXC and Qemu) in "snapshot" mode, qemu-agent is installed
- The dump is written to a samba share, that the host automounts via autofs over a 1GBit network
- Usually it takes about 1,5 hours to backup ~120GB
This is how a "normal" report looks like:

- During a normal backup, the IO load is low and the system is fully responsive
- Unfortunately several times a week, vzdump suddenly causes an extreme io load on the disks sda and sdb
- The load saturates both disks and atop shows "busy 94-99%"
This is a snapshot of atop:

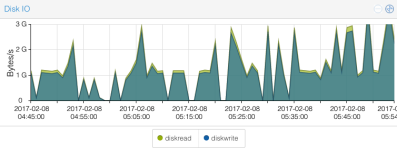
- The io-wait increases to 15% (unusual high) and the disk io shown is > 1 GBytes/s
See these diagrams taken during the backup with the crazy load:


- The reason for this is definitly not backup data written, since the network speed is not high. It rather drops to very low values

- The network is not the reason. It's not saturated during these times
- The result is: completely unresponsive systems, VMs "hanging", backup of subsequent VMs very slow (only some kB/s instead of dozens of MB/s)
Examples of some problems resulting from the crazy io situation:



- The most problematic fact is: after the end of vzdump (which in this case takes more than 12 hours instead of 1,5) the disks still go crazy and show 99% of load
Here's what the IO delay looks like when the backup finished: you see it drops from about 15% to about 8% - but the two disks still go like crazy and this system is still not usable.

- The problem can only be solved by rebooting the whole machine!!
- Right now, the backup is not usable and I disabled it (not good).
- I can't see any processes in top, atop etc. that cause this. The io load "comes out of the universe".
Let me resume: I'm not talking about bad performance because of vzdump (writing on slow NFS etc.). The vzdump triggers something causing sda and sdb go crazy, saturating the SATA-bus without even transmitting data. The effect keeps going on even after vzdump is finished and can only be stopped by rebooting.
I'm running out of ideas where too search for the problem. Maybe this is a bug.
Could it be a problem with ZFS and the cache/log SSD?