Hello everyone,
I am currently creating a home-lab cluster using Proxmox, and testing several storage back-ends to figure out the best one for a production cluster.
The production cluster will host general purpose Virtual Machines.
Would like to share my findings of a simple benchmarks conducted inside a VM with Ubuntu 22.04 Desktop installed.
Please share your thoughts whether i can consider the numbers accurate (+/-10%) or shall i dig deeper with fio.
Hardware:
All Have 2x10Gb/s bonded/Lagg ( all networks use the same backbone for public/private/cluster/ceph-private/ceph-public/gluster )
PVE Cluster with 3 nodes, each has 512GB ram 12 cores @ 2.4GHz
Ceph_ssd_pool with 3X1TB SSD OSD's ( Kingston Enterprise ) replica 3 ( raid0 backed, no JBOD support )
Gluster_pool with 3X1TB SSD Bricks ( Crucial Consumer ) replica 3, lvm, xfs ( raid0 backed, no JBOD support )
Truenas Core 12, 256GB ram, 4 cores @ 2GHz, 3way mirror vdevs with 3x3TB HDD Enterprise 7200rpm each
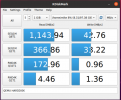
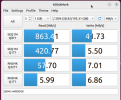
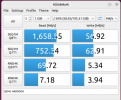
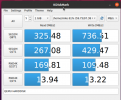
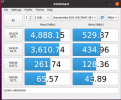
Benchmarks done via DiskMark ( .AppImage used )
Attached screenshots
My conclusion:
Seems no one can beat TruenasCore, although there are no fine-tuning in-place ( nvme metadata, SLOG, etc .. ) and all HDD's, i am positive this can be bummed by 20 to 30% if there is.
Ceph is SLOW, could get faster by adding a 100 or so nodes, but this is unrealistic for small-medium sized private clouds, however, it is a breeze to watch how it heals itself and redistributes everything, as they said it is like a living organism, and it shows you with it's dashboard all the details in real time.
It can be trusted as a production storage right away even if you do not have experience with it, just keep a 30% free space at all times and learn it as you go.
Gluster is kinda in the middle, it is fast as the local disk can be, could be probably faster when more nodes or volumes are added, hopefully not as many as Ceph needs, and using a mix of distributed and replicated pools, i will need to try that next.
The problem with Gluster is that it does not have a dashboard and it cannot be yet trusted unless you really play around with it for a while.
It is a sacrifice between High Availability and Performance, in my opinion, it looks like this
---------------------------High-Availability---------------------------------Performance-------------------------------------
----------Ceph--------------------------------------------Gluster------------------------------------------TruenasCore------
The more you need HA the more you will loose performance.
Finally,
I have been rebuilding and rebuilding my cluster to choose the best storage for my environment for months, wanting HA and Performance at the same time, then i realized there are none! no ultimate one solution that has everything, HA, Performance, Dashboard, set-and-forget ...
The best approach so far was to use all of them together, scale-out-or-in on storage basis based on the workload.
So decided to use all of them, Ceph and Gluster natevely inside Proxmox, and TruenasCore as standalone ( could be merged too but Truenas interface and ease is a killer feature )
For non-HA VM's demanding High IOPS i use primary os disk on NFS mounted TruenasCore on 3 way mirrored vdev, and secondary disks on NFS mounted TruenasCore Raidz2/3 vdev.
For HA VM's with or without High IOPS i am stuck with Gluster
For S3 object i use Ceph ( eg. Veeam Backup repositories, Web Asset Caching and CDN, .... )
Finally Finally,
There is one more play in the game that could give us the best in both worlds ( HA and Performance ), and it is Truenas Scale with Gluster!
I have tried briefly on a virtual environment, it works, but performance was obviously very poor ( no-pci pass-through used )
Hopefully someone here in the community has and can share info around that subject, otherwise will have to rebuild my cluster for the 10th time
Best
Mike
I am currently creating a home-lab cluster using Proxmox, and testing several storage back-ends to figure out the best one for a production cluster.
The production cluster will host general purpose Virtual Machines.
Would like to share my findings of a simple benchmarks conducted inside a VM with Ubuntu 22.04 Desktop installed.
Please share your thoughts whether i can consider the numbers accurate (+/-10%) or shall i dig deeper with fio.
Hardware:
All Have 2x10Gb/s bonded/Lagg ( all networks use the same backbone for public/private/cluster/ceph-private/ceph-public/gluster )
PVE Cluster with 3 nodes, each has 512GB ram 12 cores @ 2.4GHz
Ceph_ssd_pool with 3X1TB SSD OSD's ( Kingston Enterprise ) replica 3 ( raid0 backed, no JBOD support )
Gluster_pool with 3X1TB SSD Bricks ( Crucial Consumer ) replica 3, lvm, xfs ( raid0 backed, no JBOD support )
Truenas Core 12, 256GB ram, 4 cores @ 2GHz, 3way mirror vdevs with 3x3TB HDD Enterprise 7200rpm each
Benchmarks done via DiskMark ( .AppImage used )
Attached screenshots
My conclusion:
Seems no one can beat TruenasCore, although there are no fine-tuning in-place ( nvme metadata, SLOG, etc .. ) and all HDD's, i am positive this can be bummed by 20 to 30% if there is.
Ceph is SLOW, could get faster by adding a 100 or so nodes, but this is unrealistic for small-medium sized private clouds, however, it is a breeze to watch how it heals itself and redistributes everything, as they said it is like a living organism, and it shows you with it's dashboard all the details in real time.
It can be trusted as a production storage right away even if you do not have experience with it, just keep a 30% free space at all times and learn it as you go.
Gluster is kinda in the middle, it is fast as the local disk can be, could be probably faster when more nodes or volumes are added, hopefully not as many as Ceph needs, and using a mix of distributed and replicated pools, i will need to try that next.
The problem with Gluster is that it does not have a dashboard and it cannot be yet trusted unless you really play around with it for a while.
It is a sacrifice between High Availability and Performance, in my opinion, it looks like this
---------------------------High-Availability---------------------------------Performance-------------------------------------
----------Ceph--------------------------------------------Gluster------------------------------------------TruenasCore------
The more you need HA the more you will loose performance.
Finally,
I have been rebuilding and rebuilding my cluster to choose the best storage for my environment for months, wanting HA and Performance at the same time, then i realized there are none! no ultimate one solution that has everything, HA, Performance, Dashboard, set-and-forget ...
The best approach so far was to use all of them together, scale-out-or-in on storage basis based on the workload.
So decided to use all of them, Ceph and Gluster natevely inside Proxmox, and TruenasCore as standalone ( could be merged too but Truenas interface and ease is a killer feature )
For non-HA VM's demanding High IOPS i use primary os disk on NFS mounted TruenasCore on 3 way mirrored vdev, and secondary disks on NFS mounted TruenasCore Raidz2/3 vdev.
For HA VM's with or without High IOPS i am stuck with Gluster
For S3 object i use Ceph ( eg. Veeam Backup repositories, Web Asset Caching and CDN, .... )
Finally Finally,
There is one more play in the game that could give us the best in both worlds ( HA and Performance ), and it is Truenas Scale with Gluster!
I have tried briefly on a virtual environment, it works, but performance was obviously very poor ( no-pci pass-through used )
Hopefully someone here in the community has and can share info around that subject, otherwise will have to rebuild my cluster for the 10th time
Best
Mike