Hi all,
I'm running a cluster of three Proxmox nodes with replicated ZFS RAID10 pools on identical machines. Each node has 64 GB RAM, all VMs have ballooning activated.
On one of the nodes, a VM has ballooning memory set to 6 GB (minimum) and 16 GB maximum, and I see a lot of these errors in
Swap space is nearly full constantly. The VM is running Debian 10, CPU- and memory hotplugging is activated (as described in the wiki), QEMU guest agent is installed. Side note: There is one Windows 10 VM running, besides some other small VMs, on this node.
Edit: The hosts RAM is not overcommitted. Committed RAM of running VMs is currently 32 GB (ballooning max), or 20 GB (ballooning min), respectively.
Output of
My assumption is that ZFS is taking all RAM it can get, and the VM is constantly fighting against it, trying to get more pages. So far it did not seem to affect the reliability of either said VM, other VMs or the host.
Is this a known problem? Or no problem at all? I'm happy to provide more detail when necessary. Thanks!
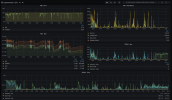
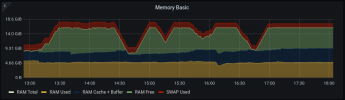
Here's a visualization of the described phenomenon (see attachment).
I'm running a cluster of three Proxmox nodes with replicated ZFS RAID10 pools on identical machines. Each node has 64 GB RAM, all VMs have ballooning activated.
On one of the nodes, a VM has ballooning memory set to 6 GB (minimum) and 16 GB maximum, and I see a lot of these errors in
dmesg inside the VM:
Code:
[1274631.052945] kworker/0:5: page allocation failure: order:0, mode:0x6310ca(GFP_HIGHUSER_MOVABLE|__GFP_NORETRY|__GFP_NOMEMALLOC), nodemask=(null)
[1274631.052947] kworker/0:5 cpuset=/ mems_allowed=0
[1274631.052953] CPU: 0 PID: 29716 Comm: kworker/0:5 Not tainted 4.19.0-16-amd64 #1 Debian 4.19.181-1
[1274631.052955] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.14.0-0-g155821a1990b-prebuilt.qemu.org 04/01/2014
[1274631.052962] Workqueue: events_freezable update_balloon_size_func [virtio_balloon]
[1274631.052964] Call Trace:
[1274631.052978] dump_stack+0x66/0x81
[1274631.052982] warn_alloc.cold.120+0x6c/0xec
[1274631.052987] __alloc_pages_slowpath+0xc73/0xcb0
[1274631.052993] ? vring_unmap_one+0x16/0x70 [virtio_ring]
[1274631.052995] __alloc_pages_nodemask+0x28b/0x2b0
[1274631.052998] update_balloon_size_func+0x109/0x2c0 [virtio_balloon]
[1274631.053002] process_one_work+0x1a7/0x3a0
[1274631.053004] worker_thread+0x30/0x390
[1274631.053006] ? create_worker+0x1a0/0x1a0
[1274631.053008] kthread+0x112/0x130
[1274631.053010] ? kthread_bind+0x30/0x30
[1274631.053013] ret_from_fork+0x35/0x40
[1274631.053038] virtio_balloon virtio0: Out of puff! Can't get 1 pagesSwap space is nearly full constantly. The VM is running Debian 10, CPU- and memory hotplugging is activated (as described in the wiki), QEMU guest agent is installed. Side note: There is one Windows 10 VM running, besides some other small VMs, on this node.
Edit: The hosts RAM is not overcommitted. Committed RAM of running VMs is currently 32 GB (ballooning max), or 20 GB (ballooning min), respectively.
Output of
pveversion -v:
Code:
# pveversion -v
proxmox-ve: 6.3-1 (running kernel: 5.4.106-1-pve)
pve-manager: 6.3-6 (running version: 6.3-6/2184247e)
pve-kernel-5.4: 6.3-8
pve-kernel-helper: 6.3-8
pve-kernel-5.4.106-1-pve: 5.4.106-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.1.0-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: 0.8.35+pve1
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.20-pve1
libproxmox-acme-perl: 1.0.8
libproxmox-backup-qemu0: 1.0.3-1
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.3-5
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.1-1
libpve-storage-perl: 6.3-8
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.0.13-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.4-9
pve-cluster: 6.2-1
pve-container: 3.3-4
pve-docs: 6.3-1
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.2-2
pve-ha-manager: 3.1-1
pve-i18n: 2.3-1
pve-qemu-kvm: 5.2.0-5
pve-xtermjs: 4.7.0-3
qemu-server: 6.3-10
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.4-pve1My assumption is that ZFS is taking all RAM it can get, and the VM is constantly fighting against it, trying to get more pages. So far it did not seem to affect the reliability of either said VM, other VMs or the host.
Is this a known problem? Or no problem at all? I'm happy to provide more detail when necessary. Thanks!
Here's a visualization of the described phenomenon (see attachment).
Attachments
Last edited: