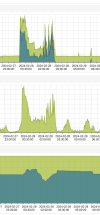
Hi. I have quite fast machines and thought that the backup process should be easily doable. but it leads to high io delay, so that the vms are consuming more and more ram, and are crashing then. Is there something i do wrong?
System:
pve-manager/8.1.3/b46aac3b42da5d15
24 x AMD Ryzen 9 5900X
128 GB DDR4 RAM
Lexar nvme SSD NM790 4 TB ( quite high IO/s ) as single disk zfs
Daily resources seem fine. backup takes place around 03:00

backup Target is a Proxmox Backup Server, conencted with 40 Gbit/s Mellanox , backup mode "snapshot"
My vms are quite big and demand some IO/s ( blockchain synchronosation ). One machine for example is 1.6 TiB. The process takes around 40 minutes
So for nvme speeds we read quite slowly: 51.0 MiB/s
The host seems fine. But the vm really does not like it


we see high io wait and high cpu usage.. the RAM is growing over 15 minutes, until its too much
i have 8 GB zfs arc - shouldn't that be enough to catch reads and writes of the vm?
any recommendations? does disk type, cache, async_io or io_thread change anything?
in my experience, a zfs replication is much less demanding. i know that is no backup, but would snapshots and replication be a better way for me?
System:
pve-manager/8.1.3/b46aac3b42da5d15
24 x AMD Ryzen 9 5900X
128 GB DDR4 RAM
Lexar nvme SSD NM790 4 TB ( quite high IO/s ) as single disk zfs
Daily resources seem fine. backup takes place around 03:00
backup Target is a Proxmox Backup Server, conencted with 40 Gbit/s Mellanox , backup mode "snapshot"
My vms are quite big and demand some IO/s ( blockchain synchronosation ). One machine for example is 1.6 TiB. The process takes around 40 minutes
INFO: Starting Backup of VM 172 (qemu)
INFO: Backup started at 2024-02-28 03:33:23
INFO: status = running
INFO: VM Name: rocketpool2
INFO: include disk 'scsi0' 'zfs2:vm-172-disk-0' 1600G
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: creating Proxmox Backup Server archive 'vm/172/2024-02-28T02:33:23Z'
INFO: issuing guest-agent 'fs-freeze' command
INFO: issuing guest-agent 'fs-thaw' command
INFO: started backup task 'a7f1d10b-b0aa-4232-a98f-ae31ea77027e'
INFO: resuming VM again
INFO: scsi0: dirty-bitmap status: OK (133.3 GiB of 1.6 TiB dirty)
INFO: using fast incremental mode (dirty-bitmap), 133.3 GiB dirty of 1.6 TiB total
INFO: 0% (404.0 MiB of 133.3 GiB) in 3s, read: 134.7 MiB/s, write: 134.7 MiB/s
INFO: 1% (1.3 GiB of 133.3 GiB) in 23s, read: 48.8 MiB/s, write: 48.8 MiB/s
INFO: 2% (2.7 GiB of 133.3 GiB) in 59s, read: 38.2 MiB/s, write: 38.2 MiB/s
...
INFO: 99% (132.0 GiB of 133.3 GiB) in 38m 55s, read: 79.8 MiB/s, write: 79.5 MiB/s
INFO: 100% (133.3 GiB of 133.3 GiB) in 39m 22s, read: 49.0 MiB/s, write: 48.9 MiB/s
INFO: backup is sparse: 16.00 MiB (0%) total zero data
INFO: backup was done incrementally, reused 1.43 TiB (91%)
INFO: transferred 133.28 GiB in 2675 seconds (51.0 MiB/s)
So for nvme speeds we read quite slowly: 51.0 MiB/s
The host seems fine. But the vm really does not like it
we see high io wait and high cpu usage.. the RAM is growing over 15 minutes, until its too much
[703702.429267] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=docker.service,mems_allowed=0,global_oom,task_memcg=/system.slice/docker-f0f94b0b0df1c57910e5575ae7ae4f17010e38cc48886bf5f69697dc2b308c8a.scope,task=lighthouse,pid=2083349,uid=0
[703702.429382] Out of memory: Killed process 2083349 (lighthouse) total-vm:40714280kB, anon-rss:9774920kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:63232kB oom_score_adj:0
i have 8 GB zfs arc - shouldn't that be enough to catch reads and writes of the vm?
options zfs zfs_arc_max=8589934592
any recommendations? does disk type, cache, async_io or io_thread change anything?
in my experience, a zfs replication is much less demanding. i know that is no backup, but would snapshots and replication be a better way for me?