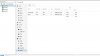
2019-04-28 02:00:05.835603 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71703 : cluster [DBG] pgmap v71690: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
2019-04-28 02:00:07.855779 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71704 : cluster [DBG] pgmap v71691: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
2019-04-28 02:00:09.875527 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71705 : cluster [DBG] pgmap v71692: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
2019-04-28 02:00:11.895626 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71706 : cluster [DBG] pgmap v71693: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
we creat new pool
later happen this is error .
please help me point right way
thanks
4 server
every server have 5*6TB sas
2019-04-28 02:00:07.855779 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71704 : cluster [DBG] pgmap v71691: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
2019-04-28 02:00:09.875527 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71705 : cluster [DBG] pgmap v71692: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
2019-04-28 02:00:11.895626 mgr.pve140 client.24111 192.168.100.140:0/3689608854 71706 : cluster [DBG] pgmap v71693: 256 pgs: 26 active+undersized+remapped, 230 undersized+peered; 0B data, 5.04GiB used, 27.3TiB / 27.3TiB avail
we creat new pool
later happen this is error .
please help me point right way
thanks
4 server
every server have 5*6TB sas
Last edited: