Hello,
We are currently looking at Promox as an alternative to our Microsoft HCI infrastructures and have the problem that we are in an HA infrastructure (2 stackable switches, so that one could fail without causing a systemfailure). Our nodes have 2x physical 100 GbE LAN and we would like to use them in a team mode (bond?) as a base for multiple virtual network connections (vmbr). So we have Ceph, Management and SDN for VMs for which we need a bridge, but want to enable this over only one network connection (bond of 2x 100 GBE NICs).
Microsoft implements this via a vswitch that is created from the two network cards on the hosts (similar to bond) and then any number of vNICs are created on the hosts (not usable for VMs, only usable for host connections) which then use the VSwitch as a connector to the physical network. Then you create a vNIC for storage S2D (Ceph), one for management (vmbr) which you then also use as a gateway for the SDN infrastructure. What is the best practice approach at Proxmox for such a HA HCI infrastructure with only two physical network cards?
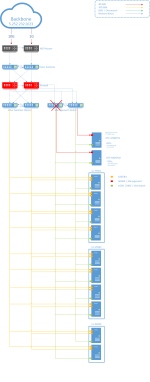
Network topology: As you can see in the schematic in the attachment, we use 2x 100 GBE NICs per node and map the Mngmt LAN (host connectrion), two storage networks and the SDN over them. In the case of MS, the two pNICs are combined with a VSwitch to form a switch-independent team. Several vNICs are then generated on this VSwitch, which can then be used for the individual functions (SDN + S2D). Since the video tutorials only cover LAB environments without HA Network infrastructure, I need to evaluate in advance if Proxmox can be used in our topology.
Thank you so far. Best regards!
We are currently looking at Promox as an alternative to our Microsoft HCI infrastructures and have the problem that we are in an HA infrastructure (2 stackable switches, so that one could fail without causing a systemfailure). Our nodes have 2x physical 100 GbE LAN and we would like to use them in a team mode (bond?) as a base for multiple virtual network connections (vmbr). So we have Ceph, Management and SDN for VMs for which we need a bridge, but want to enable this over only one network connection (bond of 2x 100 GBE NICs).
Microsoft implements this via a vswitch that is created from the two network cards on the hosts (similar to bond) and then any number of vNICs are created on the hosts (not usable for VMs, only usable for host connections) which then use the VSwitch as a connector to the physical network. Then you create a vNIC for storage S2D (Ceph), one for management (vmbr) which you then also use as a gateway for the SDN infrastructure. What is the best practice approach at Proxmox for such a HA HCI infrastructure with only two physical network cards?
Network topology: As you can see in the schematic in the attachment, we use 2x 100 GBE NICs per node and map the Mngmt LAN (host connectrion), two storage networks and the SDN over them. In the case of MS, the two pNICs are combined with a VSwitch to form a switch-independent team. Several vNICs are then generated on this VSwitch, which can then be used for the individual functions (SDN + S2D). Since the video tutorials only cover LAB environments without HA Network infrastructure, I need to evaluate in advance if Proxmox can be used in our topology.
Thank you so far. Best regards!