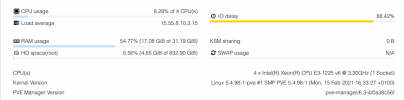
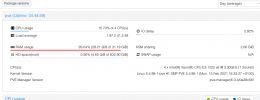
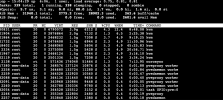
Hi everyone, after the last updates I noticed that the cluster in particular the main node, after about 30 minutes, starts to occupy 95% of the memory. This never happened, where can I inquire?
proxmox-ve: 6.3-1 (running kernel: 5.4.98-1-pve) pve-manager: 6.3-4 (running version: 6.3-4/0a38c56f) pve-kernel-5.4: 6.3-5 pve-kernel-helper: 6.3-5 pve-kernel-5.3: 6.1-6 pve-kernel-5.0: 6.0-11 pve-kernel-5.4.98-1-pve: 5.4.98-1 pve-kernel-5.4.78-2-pve: 5.4.78-2 pve-kernel-5.4.78-1-pve: 5.4.78-1 pve-kernel-5.3.18-3-pve: 5.3.18-3 pve-kernel-5.0.21-5-pve: 5.0.21-10 pve-kernel-5.0.15-1-pve: 5.0.15-1 ceph-fuse: 12.2.11+dfsg1-2.1+b1 corosync: 3.1.0-pve1 criu: 3.11-3 glusterfs-client: 5.5-3 ifupdown: 0.8.35+pve1 ksm-control-daemon: 1.3-1 libjs-extjs: 6.0.1-10 libknet1: 1.20-pve1 libproxmox-acme-perl: 1.0.7 libproxmox-backup-qemu0: 1.0.3-1 libpve-access-control: 6.1-3 libpve-apiclient-perl: 3.1-3 libpve-common-perl: 6.3-4 libpve-guest-common-perl: 3.1-5 libpve-http-server-perl: 3.1-1 libpve-storage-perl: 6.3-7 libqb0: 1.0.5-1 libspice-server1: 0.14.2-4~pve6+1 lvm2: 2.03.02-pve4 lxc-pve: 4.0.6-2 lxcfs: 4.0.6-pve1 novnc-pve: 1.1.0-1 proxmox-backup-client: 1.0.8-1 proxmox-mini-journalreader: 1.1-1 proxmox-widget-toolkit: 2.4-5 pve-cluster: 6.2-1 pve-container: 3.3-4 pve-docs: 6.3-1 pve-edk2-firmware: 2.20200531-1 pve-firewall: 4.1-3 pve-firmware: 3.2-2 pve-ha-manager: 3.1-1 pve-i18n: 2.2-2 pve-qemu-kvm: 5.2.0-2 pve-xtermjs: 4.7.0-3 qemu-server: 6.3-5 smartmontools: 7.1-pve2 spiceterm: 3.1-1 vncterm: 1.6-2 zfsutils-linux: 2.0.3-pve1
proxmox-ve: 6.3-1 (running kernel: 5.4.98-1-pve) pve-manager: 6.3-4 (running version: 6.3-4/0a38c56f) pve-kernel-5.4: 6.3-5 pve-kernel-helper: 6.3-5 pve-kernel-5.3: 6.1-6 pve-kernel-5.0: 6.0-11 pve-kernel-5.4.98-1-pve: 5.4.98-1 pve-kernel-5.4.78-2-pve: 5.4.78-2 pve-kernel-5.4.78-1-pve: 5.4.78-1 pve-kernel-5.3.18-3-pve: 5.3.18-3 pve-kernel-5.0.21-5-pve: 5.0.21-10 pve-kernel-5.0.15-1-pve: 5.0.15-1 ceph-fuse: 12.2.11+dfsg1-2.1+b1 corosync: 3.1.0-pve1 criu: 3.11-3 glusterfs-client: 5.5-3 ifupdown: 0.8.35+pve1 ksm-control-daemon: 1.3-1 libjs-extjs: 6.0.1-10 libknet1: 1.20-pve1 libproxmox-acme-perl: 1.0.7 libproxmox-backup-qemu0: 1.0.3-1 libpve-access-control: 6.1-3 libpve-apiclient-perl: 3.1-3 libpve-common-perl: 6.3-4 libpve-guest-common-perl: 3.1-5 libpve-http-server-perl: 3.1-1 libpve-storage-perl: 6.3-7 libqb0: 1.0.5-1 libspice-server1: 0.14.2-4~pve6+1 lvm2: 2.03.02-pve4 lxc-pve: 4.0.6-2 lxcfs: 4.0.6-pve1 novnc-pve: 1.1.0-1 proxmox-backup-client: 1.0.8-1 proxmox-mini-journalreader: 1.1-1 proxmox-widget-toolkit: 2.4-5 pve-cluster: 6.2-1 pve-container: 3.3-4 pve-docs: 6.3-1 pve-edk2-firmware: 2.20200531-1 pve-firewall: 4.1-3 pve-firmware: 3.2-2 pve-ha-manager: 3.1-1 pve-i18n: 2.2-2 pve-qemu-kvm: 5.2.0-2 pve-xtermjs: 4.7.0-3 qemu-server: 6.3-5 smartmontools: 7.1-pve2 spiceterm: 3.1-1 vncterm: 1.6-2 zfsutils-linux: 2.0.3-pve1