Hello,
We've been using Proxmox for years now and really like the latest version.
A few bugs that appear annoying:
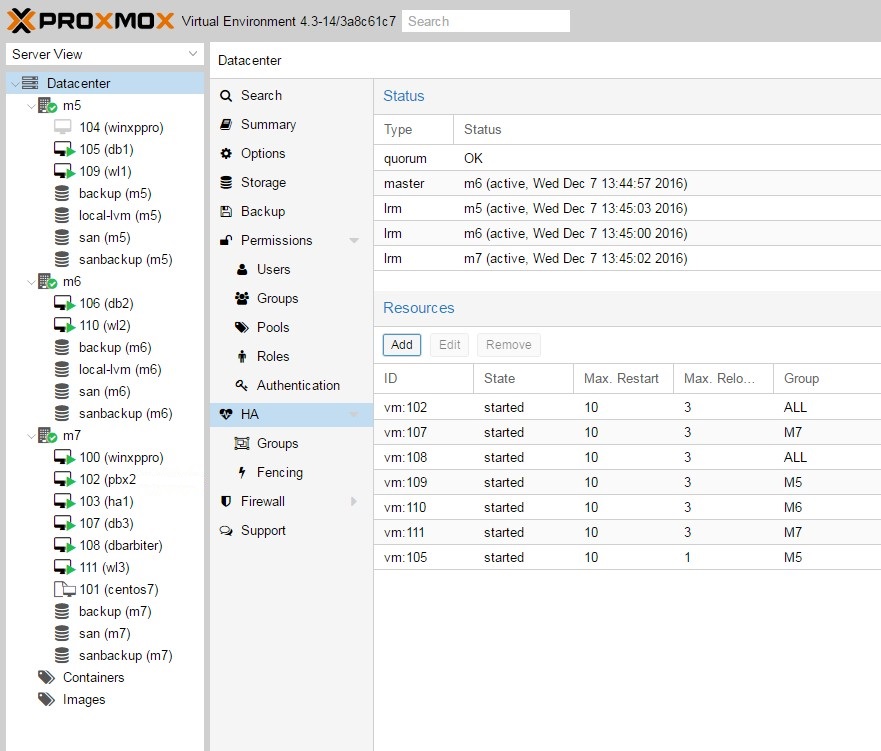
(1) When restarting a node using the web interface in a multi-node cluster, any running non-HA VMs are not automatically live-migrated from that node to any other node. I would expect that any VMs with shared storage should be migrated to any other compatible node in the cluster. In the case of a HA VM, the VM is migrated, but it is first shutdown on the node that is being shutdown and then later restarted on another node. Why not live migrate the HA VM to another node before the restart instead?
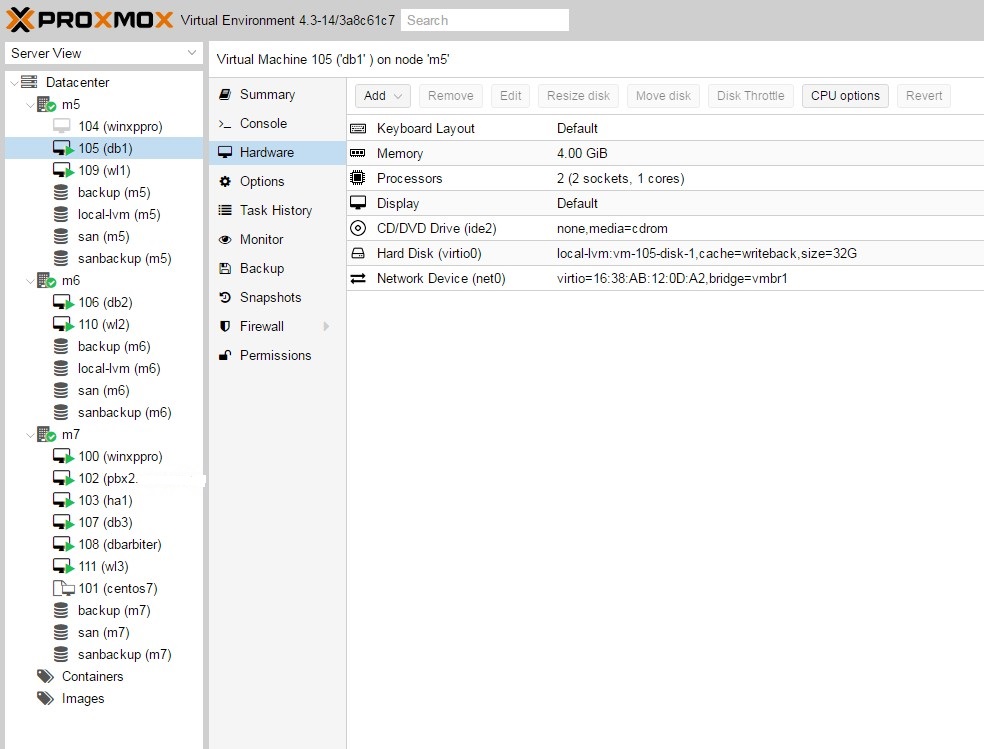
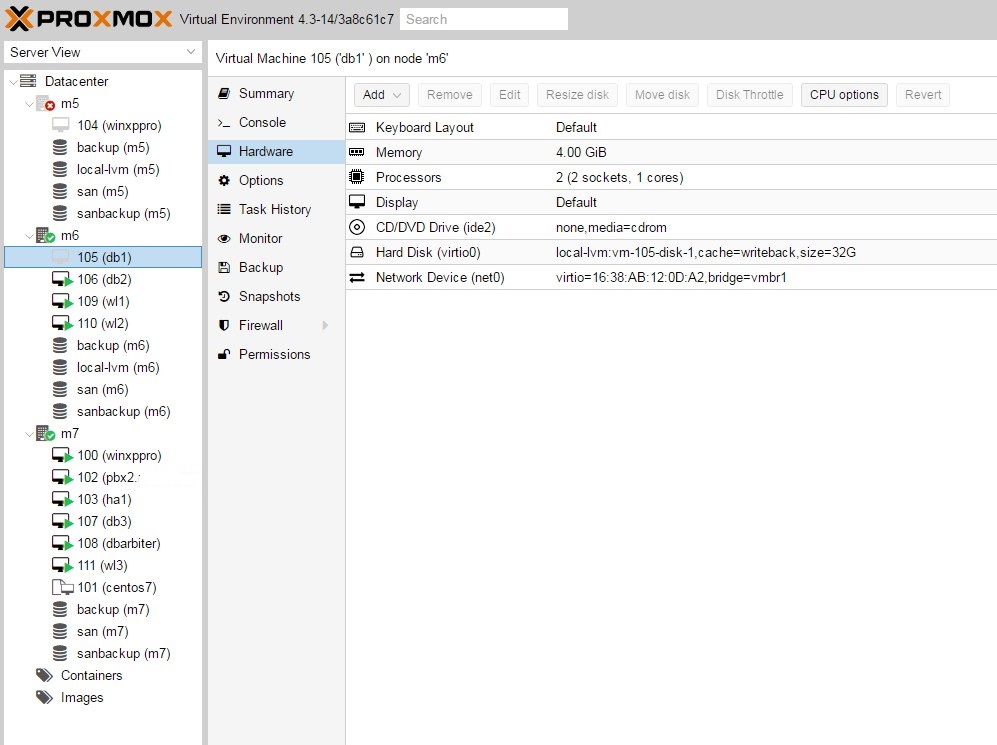
(2) An HA VM on non-shared storage (e.g. local-lvm-thin) is still automatically migrated to another node when the node on which it was originally started is being shutdown. The HA VM can then no longer be restarted even if the original node comes back up. I have to manually move the XXX.conf file from node A to node B, e.g. /etc/pve/nodes/A/qemu-server/XXX.conf to /etc/pve/nodes/B/qemu-server/XXX.conf in order to be able to restart it from the web interface again.
Thank you.
Regards,
Stephan.
We've been using Proxmox for years now and really like the latest version.
A few bugs that appear annoying:
(1) When restarting a node using the web interface in a multi-node cluster, any running non-HA VMs are not automatically live-migrated from that node to any other node. I would expect that any VMs with shared storage should be migrated to any other compatible node in the cluster. In the case of a HA VM, the VM is migrated, but it is first shutdown on the node that is being shutdown and then later restarted on another node. Why not live migrate the HA VM to another node before the restart instead?
(2) An HA VM on non-shared storage (e.g. local-lvm-thin) is still automatically migrated to another node when the node on which it was originally started is being shutdown. The HA VM can then no longer be restarted even if the original node comes back up. I have to manually move the XXX.conf file from node A to node B, e.g. /etc/pve/nodes/A/qemu-server/XXX.conf to /etc/pve/nodes/B/qemu-server/XXX.conf in order to be able to restart it from the web interface again.
Thank you.
Regards,
Stephan.