TErxleben's latest activity
-
TTErxleben replied to the thread Massenstart von VMs und Container.Ein beherztes journalctl --list-boots zeigte dann tatsächlich 150 Neustarts in drei Tagen. Das erklärt natürlich die Einträge im Tasklog. Es handelt sich um einen HP Elitedesk G800 G4 im Headless-Betrieb. Die Lösung gegen die willenlosen Reboots...
-
TIm Zuge des e1000-Generves habe ich einem Kandidaten mal eine zusätzlicheM2- 2.5GB-Realtek (8125) verpasst. Diese ist als Pimary definiert. Dann habe ich ein Bond (active-backup) erstellt. Ziehe ich nun das Kabel, übernimmt die e1000 auch brav...
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Es ging nur darum, dass es immer noch genügend Probleme jenseits des Dateisystems gibt. Du hast behauptet, man würde sich Monate Suche sparen, sofern man ZFS nutzt,
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Ich wettere weder gegen ZFS und noch weniger gegen Redundanz. Wie du aber selbst feststellst: Werden hier gerne Prinzessinnenschlösser angepriesen.
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Also ein Rechner, ein Netzteil und ein einzelner Kabel(strang) liefert nicht? Das ist natürlich eine extrem fiese Möpp.
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Wie kann es passieren, das in einer Maschine nur die Hälfte der Disks ausfallen?
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Wir reden doch aneinander vorbei. wenn ich ein ausgewachsenes zentrales Storagesystem betreibe, dann selbstverständlich mit passenden RAID-Techniken. selbige wachen nur über die HW-Verfügbarkeiten, da sie von den benutzenden Dateisystemen keine...
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Komische Argumentation. Wenn ich ein storage mit 500TB habe, ist ein passender RAID-Controller natürlich genau die richtige Lösung um Hochverfügbarkeit zu gewährleisten. Wenn ich eine Einzelmaschine betrachte, sieht das anders aus. Richtig...
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Ach? du benutzt ZFS auf einer Einzelplatte? Oder sind zwei statt einer Platte nicht doch eine Verdoppelung? Das ist einfach dumm Tüch oder ein sehr sehr obskurer Controller.
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Das waren dann wohl netzweit verfügbare Member?
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Das ist doch Augenwischerei. Mit ZFS verdoppelst du mindestens die POFs. Zusätzlich erbst du Fehler, die im ZFS-Layer selbst stecken. Es soll sogar HW-Raid-Controller geben, die so ihre eigenen Macken haben. Wenn meine einzelne Platte ausfällt...
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Im Fehlerfall schon mal einen ZFS-Member umgestöpselt, wenn es eben nicht mehr "einfach" seinen Dienst tut? Hau raus wie das geht!
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.Wenn es sofort auffällt machst du was? ZFS endlich als Lösung aller Probleme? Lösen sich Probleme plötzlich in Luft auf? P.S.: Schweine mit unterschiedlichen Namen werden schon sehr lange durchs Dorf getrieben!
-
TTErxleben replied to the thread Proxmox regelmäßig nicht erreichbar.In meinen Augen, ist das seit mindestens 4 Dekaden repetierte Redundanzgeplapper eigentlich eher kontraproduktiv. Selbst ein Raid ist eine Fehlerquelle, die selten nötig ist und eher zu Komplikationen führt. Wer hat denn übrigens noch einen...
-
TTErxleben replied to the thread Benachrichtigung bei VM-Ausfall.Nochmal nachgedengelt. Da ich mit dem Script auch meinen DNS/DHCP-Server (Pihole) redundant halte, kann man sich natürlich mächtig ins Knie schießen, falls der nicht aus dem Kreuz kommt. So habe ich nun einen Mischbetrieb zwischen Fester IP und...
-
TTErxleben replied to the thread Massenstart von VMs und Container.Keine Hookscripts. Lediglich die vorhin geposteten Scripte mittels systemd. failover.sh läuft in einer Endlosschleife und refreshcoldstandby.sh zeitgesteuert um 15:30
-
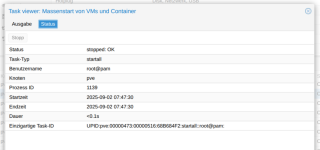
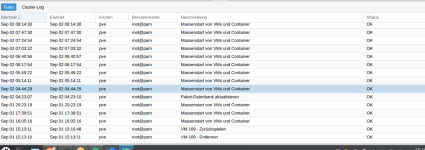
TTErxleben replied to the thread Massenstart von VMs und Container.Die Ausgabe der Tasks zeigen nur TASK OK Es gibt nur zwei Scripte, die allerdings auf diversen anderen Hosts laufen, auf den es nicht die seltsamen Taskausgaben gibt: root@pve:~# cat failover.sh #!/bin/bash # Failover für Proxmox-hosts. #...
-
TTErxleben replied to the thread Massenstart von VMs und Container.Kein Node startet beim Boot. journalctl zeigt keine Auffälligkeiten. root@pve:~# pveversion -v proxmox-ve: 9.0.0 (running kernel: 6.14.11-1-pve) pve-manager: 9.0.6 (running version: 9.0.6/49c767b70aeb6648) proxmox-kernel-helper: 9.0.4...
-
-
TTErxleben replied to the thread Massenstart von VMs und Container.Ist ein Singlehost. root@pve:~# cat /etc/pve/qemu-server/1 103.conf 107.conf 108.conf 109.conf 111.conf 112.conf root@pve:~# cat /etc/pve/qemu-server/109.conf agent: 1 boot: order=virtio0 cores: 4 memory: 2048 meta...
-
-
Ttaucht in meiner Taskliste unregelmäßig auf. Gerne 10 mal in 4h. Gestartet wird aber nichts. Wo kann die Meldung herkommen? Auf dem 9.0.6-Host sind zwar 8 VMs/Container installiert aber alle sind standardmäßig ausgeschaltet.