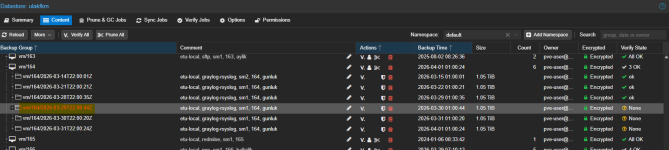
2026-04-18T14:33:54+03:00: verify ulakfkm:vm/147/2026-04-12T04:03:34Z
2026-04-18T14:33:54+03:00: check qemu-server.conf.blob
2026-04-18T14:33:54+03:00: check drive-scsi1.img.fidx
2026-04-18T23:37:37+03:00: verified 1929315.07/2029084.00 MiB in 32622.67 seconds, speed 59.14/62.20 MiB/s (107 errors)
2026-04-18T23:37:37+03:00: verify ulakfkm:vm/147/2026-04-12T04:03:34Z/drive-scsi1.img.fidx failed: chunks could not be verified
root@pbs1:~# journalctl --since "2026-04-18T14:33:54+03:00" --until "2026-04-18T23:37:37+03:00" --no-pager | grep failed
Apr 18 17:08:10 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 17:08:14 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 17:08:14 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 17:08:22 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 17:08:26 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 17:08:47 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:04:56 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (Connect)
Apr 18 20:04:56 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (Connect)
Apr 18 20:04:57 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (Connect)
Apr 18 20:05:05 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:05:30 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:06:20 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:06:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:06:29 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:06:48 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:07:16 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:08:22 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:08:33 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:09:06 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:09:54 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:11:45 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:11:52 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:12:36 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:17:15 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:17:21 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:18:31 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:18:38 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:19:31 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:35:23 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:35:44 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:35:55 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:37:24 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:37:28 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:37:44 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:01 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:06 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:08 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:23 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:32 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:38:57 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:39:37 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:39:38 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:42:04 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:43:01 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:43:19 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:45:15 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:45:32 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:45:45 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:49:40 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:49:47 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:49:52 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:54:31 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:55:06 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:55:12 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:55:16 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:55:55 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:56:04 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 20:56:14 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:05:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:05:34 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (Connect)
Apr 18 21:08:22 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:08:30 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:10:13 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:11:03 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:11:07 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:11:07 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:11:26 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:11:30 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:12:38 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:13:17 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:13:18 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:13:31 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:15:19 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:15:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:15:38 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:15:59 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:16:24 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:17:06 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:17:38 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:18:59 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:19:01 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:41:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:41:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:41:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:41:27 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:41:43 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - error reading a body from connection
Apr 18 21:42:51 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:54:51 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:56:14 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 21:58:50 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:02:18 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:03:00 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:05:20 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:10:17 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:10:22 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:13:58 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:14:35 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:18:39 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:23:20 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:23:21 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:23:50 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:31:53 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:43:12 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:45:03 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:45:13 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:45:31 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
Apr 18 22:45:35 pbs1 proxmox-backup-proxy[2299]: can't verify chunk, load failed - client error (SendRequest)
root@pbs1:~#